El aprendizaje federado (Federated Learning, FL) y los datos sintéticos son dos enfoques innovadores en la gestión y utilización de datos para entrenar modelos de inteligencia artificial (IA).
Ambos tienen el objetivo de preservar la privacidad y mejorar la seguridad de la información, pero lo hacen de formas fundamentalmente distintas. En este artículo, exploraremos las diferencias clave entre estos dos enfoques y analizaremos las ventajas del aprendizaje federado sobre el uso de datos sintéticos.
¿Qué son los datos sintéticos?
Los datos sintéticos son información generada artificialmente mediante algoritmos y modelos de IA en lugar de ser recopilada directamente de usuarios o sistemas reales. Se crean replicando las características estadísticas de los datos reales para preservar su estructura sin revelar información confidencial.
Estos datos se utilizan en múltiples aplicaciones, incluyendo el entrenamiento de modelos de machine learning, pruebas de software y análisis de escenarios hipotéticos.
¿Cómo funciona el Aprendizaje Federado?
El aprendizaje federado permite entrenar modelos de IA en múltiples dispositivos o servidores sin necesidad de transferir los datos a un repositorio central. En lugar de compartir datos sin procesar, los modelos se entrenan localmente en cada entidad participante y solo se comparten actualizaciones del modelo con el servidor central, lo que reduce significativamente los riesgos de privacidad y cumplimiento normativo.
Diferencias clave entre Aprendizaje Federado y Datos Sintéticos
- Fuente de los datos:
- Aprendizaje Federado: Utiliza datos reales en dispositivos locales sin moverlos.
- Datos Sintéticos: Genera datos artificiales que imitan patrones estadísticos de datos reales.
- Privacidad y seguridad:
- Aprendizaje Federado: Mantiene los datos en su ubicación original, minimizando la exposición de información sensible.
- Datos Sintéticos: Aunque no contienen información real, pueden fallar en replicar la complejidad de los datos originales y presentar sesgos ocultos.
- Fidelidad a la realidad:
- Aprendizaje Federado: Los modelos se entrenan con datos reales, lo que asegura una mayor precisión y representatividad.
- Datos Sintéticos: Pueden perder detalles importantes y no siempre reflejan correctamente todas las correlaciones presentes en los datos reales.
- Cumplimiento normativo:
- Aprendizaje Federado: Facilita el cumplimiento de regulaciones como GDPR y HIPAA al no centralizar datos personales.
- Datos Sintéticos: Pueden mitigar riesgos de privacidad, pero aún pueden estar sujetos a regulaciones si los modelos generativos utilizados para su creación provienen de datos personales.
- Eficiencia en el entrenamiento de modelos:
- Aprendizaje Federado: Permite modelos más precisos y robustos al aprovechar los datos originales en su contexto real.
- Datos Sintéticos: Pueden ser útiles cuando no se tienen suficientes datos reales, pero pueden generar modelos menos precisos debido a la falta de autenticidad de los datos.
Ventajas del Aprendizaje Federado frente a los Datos Sintéticos
- Mayor precisión y calidad del modelo: Al trabajar directamente con datos reales, el aprendizaje federado genera modelos más fiables y efectivos.
- Mejor cumplimiento normativo: Reduce la necesidad de anonimizar o modificar datos, manteniendo el control de la privacidad.
- Protección frente a ataques adversariales: Los datos sintéticos pueden ser vulnerables a ataques de reidentificación, mientras que el aprendizaje federado minimiza la exposición de información sensible.
- Menor riesgo de sesgo: Dado que los datos sintéticos dependen de la calidad del conjunto de entrenamiento original, pueden amplificar sesgos existentes. En cambio, el aprendizaje federado trabaja directamente con los datos sin necesidad de generarlos artificialmente.
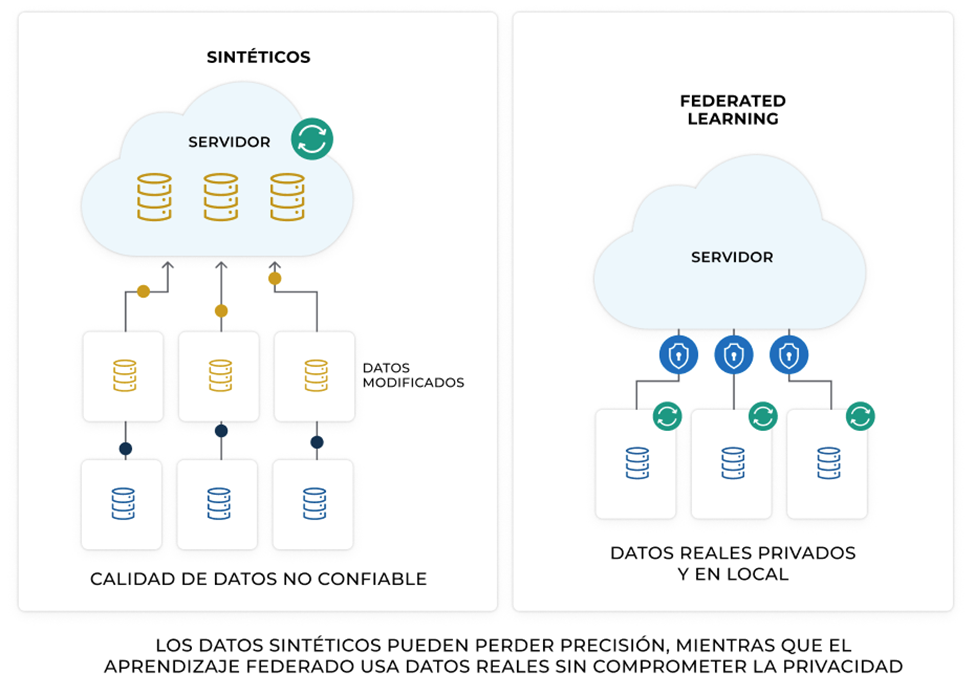
Si bien los datos sintéticos pueden ser útiles en escenarios específicos donde los datos reales son limitados o presentan restricciones legales, el aprendizaje federado es una solución más efectiva para entrenar modelos de IA preservando la privacidad y garantizando la calidad de los resultados.
Empresas y organizaciones que buscan maximizar el valor de sus datos sin comprometer la seguridad y el cumplimiento normativo encontrarán en el aprendizaje federado una alternativa más robusta y confiable.