
En plena era de la inteligencia artificial y la economía del dato, la necesidad de proteger la privacidad de las personas no solo se ha convertido en una obligación legal, sino también en un imperativo ético y competitivo. Las empresas que gestionan datos sensibles —como hospitales, entidades financieras, operadoras de telecomunicaciones o instituciones públicas— se enfrentan a un dilema constante a la hora de querer colaborar entre distintos silos de datos: ¿cómo extraer valor de sus datos sin vulnerar la privacidad ni incumplir las regulaciones?
Durante años, la anonimización de datos ha sido la técnica más extendida para tratar de resolver este problema. Sin embargo, el contexto actual exige soluciones mucho más robustas.
Es aquí donde el Aprendizaje Federado emerge como una alternativa disruptiva y mucho más eficaz. En este artículo, analizaremos las diferencias clave entre ambas aproximaciones, sus ventajas e inconvenientes, y explicaremos por qué nuestra plataforma de IA es la más privada y segura.
¿Qué es la anonimización de datos?
La anonimización de datos es un proceso mediante el cual los datos personales son transformados para que ya no puedan vincularse directamente con una persona identificable.
Esto se suele hacer mediante técnicas como:
Eliminación de identificadores directos (nombre, DNI, email…)
Enmascaramiento o pseudonimización
Generalización o agregación de valores
La idea es que una vez anonimizado un conjunto de datos, estos puedan ser utilizados para análisis estadísticos o entrenamiento de modelos de IA sin vulnerar la privacidad de los individuos.
Sin embargo, la anonimización tiene grandes limitaciones.
Las limitaciones críticas de la anonimización
Riesgo de reidentificación
Diversos estudios han demostrado que los datos anónimos pueden ser fácilmente reidentificados cuando se combinan con otras fuentes. Un caso famoso es el de Netflix: se publicó un conjunto de datos “anónimos” sobre puntuaciones de películas, que luego fue cruzado con perfiles públicos de IMDb, permitiendo identificar a usuarios concretos.Pérdida de valor analítico
Al eliminar o transformar información sensible, los datos pierden precisión y granularidad. Esto afecta directamente a la calidad del análisis y al rendimiento de los modelos de IA entrenados con ellos.No cumple totalmente con el GDPR
El Reglamento General de Protección de Datos (RGPD) de la UE indica que si los datos pueden ser reidentificados con medios razonables, no se consideran realmente anónimos. Es decir, la anonimización mal aplicada puede seguir considerándose un tratamiento de datos personales, con todas las obligaciones legales asociadas.No es escalable ni reutilizable
Los procesos de anonimización de datos suelen ser ad hoc, costosos y poco flexibles. Si cambian los objetivos analíticos, a menudo es necesario volver a anonimizar los datos desde cero.Alto consumo energético
La anonimización de datos no es gratuita desde el punto de vista computacional. Requiere pipelines de procesamiento intensivo para detectar, transformar y validar los datos sensibles. A esto se suman los costes energéticos de mover, almacenar y gestionar múltiples versiones de los datos anonimizados. En comparación con el aprendizaje federado —que entrena directamente sobre los datos en su lugar de origen y evita duplicaciones—, la anonimización representa una solución más ineficiente desde el punto de vista energético y operativo.
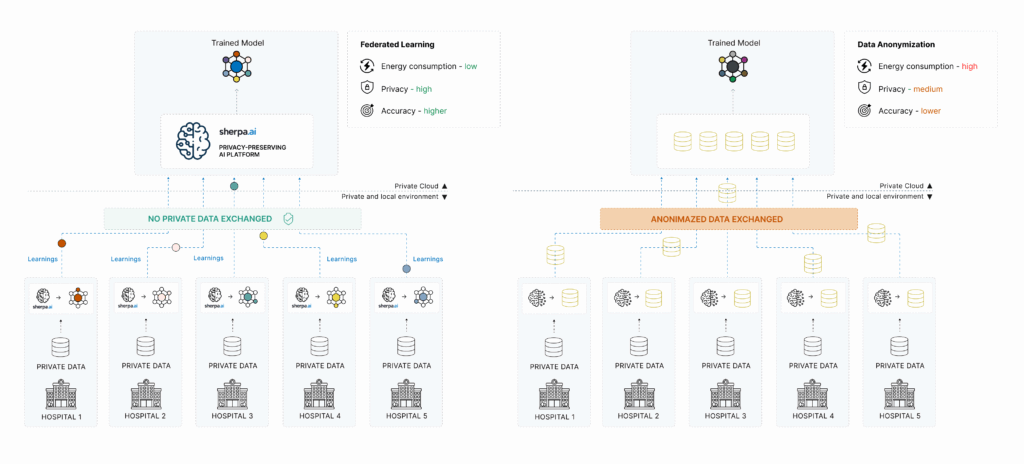
¿Qué es el Aprendizaje Federado?
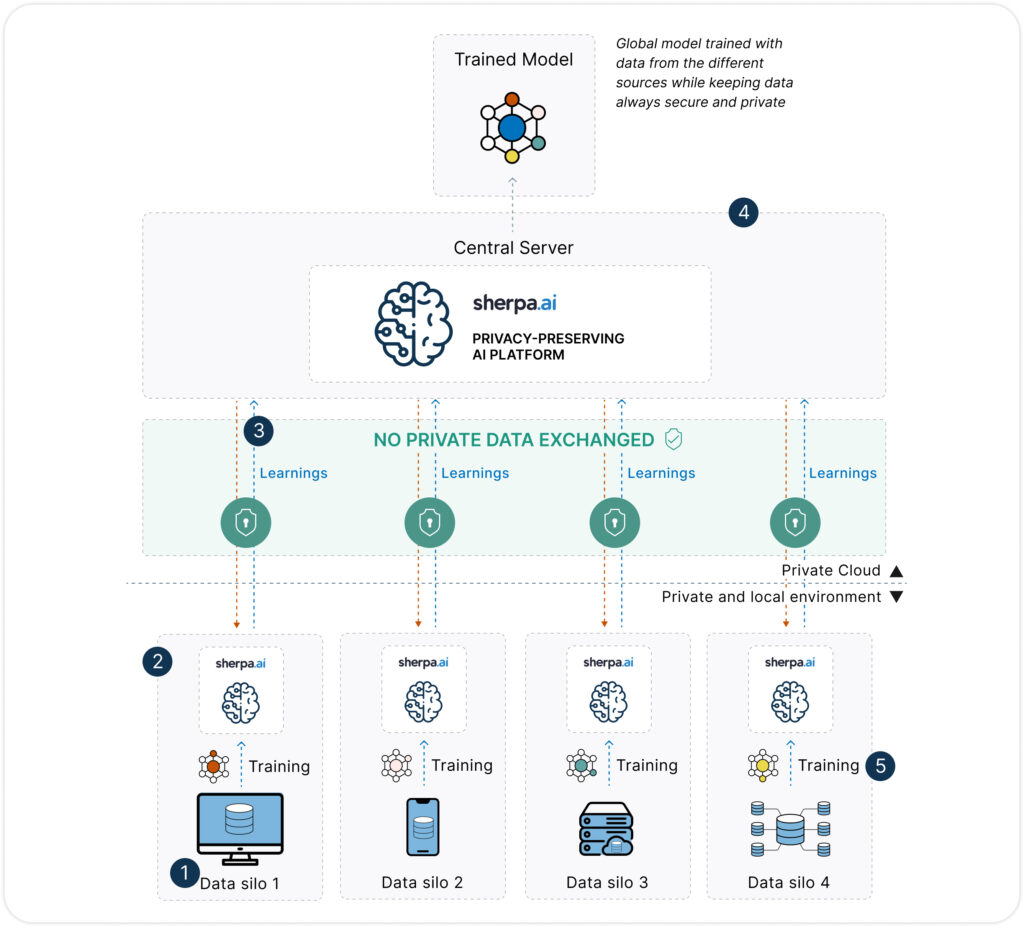
Es una técnica de entrenamiento de modelos de IA que permite construir modelos colaborativos sin necesidad de centralizar los datos. En lugar de mover los datos a un servidor central, el modelo se entrena localmente en cada nodo (hospital, banco, operador, etc.), y solo se comparten los parámetros del modelo —no los datos— con un servidor de coordinación.
La magia está en que los datos nunca abandonan su origen, lo cual cambia radicalmente el enfoque tradicional de la analítica.
Si quieres aprender más, consulta aquí
Ventajas frente a la anonimización de datos
| Categoría / Dimensión | Nuestra Plataforma | Anonimización de Datos |
|---|---|---|
| Privacidad | ||
| Privacidad y seguridad | ✅ Alta: los datos no se transfieren. Solo viajan parámetros del modelo. | ⚠️ Riesgo residual: técnicas como k-anonymity no garantizan protección absoluta. |
| Anonimización previa (PII) | ✅ No necesaria. | ❌ Imprescindible: requiere técnicas formales (k-anonymity, l-diversity…). |
| Cumplimiento normativo (GDPR) | ✅ Sólido: se alinea con GDPR, HIPAA, etc. al no mover datos personales. | ⚠️ Riesgoso: no todas las formas de anonimización se consideran adecuadas legalmente. |
| Costes y Rendimiento | ||
| Transmisión de datos | ✅ No: los datos nunca abandonan su origen. | ❌ Sí: los datos anonimizados deben enviarse a un servidor central. |
| Consumo energético | ⚡ Eficiente: sin duplicación ni pasos intermedios. | 🔋 Medio-alto: anonimización intensiva + procesamiento en servidor. |
| Calidad del modelo | ✅ Alta: se entrena con datos reales distribuidos, manteniendo riqueza y contexto. | ⚠️ Puede degradarse: la anonimización puede eliminar o distorsionar información clave. |
| Tiempos de entrenamiento | ⏱️ ✅ Razonables: permite entrenamiento local y en paralelo. | ⏱️ Variables: anonimización puede ser lenta, aunque el entrenamiento posterior es directo. |
| Coste, Escalabilidad e Interpretabilidad | ||
| Coste de implementación | ✅ Bajo: no requiere duplicación, envío, ni limpieza de datos personales. | ❌ Medio-alto: herramientas de anonimización, auditorías, almacenamiento centralizado. |
| Escalabilidad | ✅ Alta: adaptable a dispositivos, edge, hospitales, etc. | ⚠️ Limitada: depende de infraestructura central y ancho de banda. |
En resumen: el Aprendizaje Federado no solo resuelve las limitaciones de la anonimización, sino que permite abrir nuevas posibilidades de colaboración y monetización responsable del dato.
RGPD: Por qué la anonimización no siempre es suficiente
Según el Reglamento General de Protección de Datos (RGPD), los datos verdaderamente anonimizados dejan de considerarse datos personales, por lo que quedarían exentos de las restricciones normativas. Sin embargo, en la práctica, la mayoría de lo que se etiqueta como «anonimización» es en realidad seudonimización o desidentificación reversible. Si existe una forma razonable de reidentificar a una persona, los datos siguen estando sujetos a las obligaciones del RGPD.
Esto supone un riesgo importante para las organizaciones que utilizan técnicas de anonimización, ya que deben demostrar —con evidencias sólidas— que la reidentificación es prácticamente imposible. Y lo cierto es que lograr una anonimización irreversible y útil para IA es extremadamente difícil: muchos expertos coinciden en que ningún conjunto de datos útil es 100% anónimo.
El Aprendizaje Federado, en cambio, evita estos desafíos desde el principio:
No se comparte ningún dato personal, solo se intercambian parámetros del modelo.
Se alinea de forma natural con los principios del RGPD, como minimización de datos y privacidad desde el diseño (privacy by design).
Los procesos legales se simplifican, ya que cada parte sigue siendo responsable del tratamiento de sus propios datos.
La legislación emergente, como la Ley Europea de Inteligencia Artificial (EU AI Act), favorece explícitamente métodos que reduzcan el intercambio de datos sensibles, lo que convierte al FL en una estrategia alineada con el cumplimiento normativo.
Por supuesto también debe incorporar salvaguardas adecuadas: proteger los datos locales, evitar fugas de información a través de los modelos y aplicar técnicas como privacidad diferencial o agregación segura. Sin embargo, frente a la anonimización, el riesgo legal es considerablemente menor.
Nuestra plataforma refuerza este cumplimiento con funcionalidades específicas:
Registro completo y auditable de todo el proceso de entrenamiento federado,
Evaluaciones de impacto en privacidad (DPIAs) integradas,
Soporte para privacidad diferencial, cifrado y agregación segura.
Comparativa de cumplimiento RGPD
| Requisito | Nuestra Plataforma | Anonimización de Datos |
|---|---|---|
| No se comparten datos brutos | ✅Si | ❌No |
| Los datos permanecen bajo control local | ✅Si | ❌No |
| Facilidad para demostrar cumplimiento | ✅Si | ❌No |
| Riesgo de reidentificación | ✅ Muy bajo | ⚠️ Moderado a alto |
| Cumple con el principio de “privacidad desde el diseño” | ✅Si | ❌No |
| Exención del RGPD (datos dejan de ser personales) | ✅ No necesaria | ❌ Solo si se logra anonimización total |
| Flujo de privacidad auditable extremo a extremo | ✅ (funcionalidad de Sherpa.ai) | ❌ Requiere pruebas externas |
| Alineado con el futuro marco legal europeo (AI Act) | ✅Si | ❌No |
Casos se supera a la anonimización de datos
Salud: colaboración entre hospitales para entrenar modelos de diagnóstico sin compartir historiales clínicos. La anonimización aquí es especialmente débil: un historial clínico con fechas y síntomas puede ser reidentificable con relativa facilidad.
Banca y seguros: detección de fraude en red o scoring de crédito entre bancos sin tener que cruzar bases de datos. La anonimización de datos financieros es muy compleja y fácilmente reversible.
Telco: monetización de patrones de movilidad o consumo con terceros (ayuntamientos, plataformas publicitarias) sin que los datos personales salgan del entorno del operador.
La plataforma más avanzada del mercado
En este contexto, Sherpa.ai ha desarrollado la plataforma de IA Federada más potente y completa de Europa, diseñada específicamente para resolver los retos de privacidad, seguridad y cumplimiento normativo en los sectores más exigentes.
¿Qué hace única a nuestra Plataforma?
Privacidad diferencial integrada: no solo se entrena sin compartir datos, sino que además se aplican perturbaciones matemáticas para evitar la reconstrucción del dato a partir de los parámetros del modelo.
Control total por parte del cliente: los datos nunca salen del entorno del cliente. La plataforma puede desplegarse en sus instalaciones o en nube privada, garantizando la soberanía del dato.
Auditoría y trazabilidad: la solución incluye herramientas para registrar y demostrar que se cumple con el GDPR, la Ley de IA de la UE y otras normativas sectoriales.
Alta interoperabilidad y rendimiento: compatible con distintos frameworks de IA (TensorFlow, PyTorch, etc.), orquestación avanzada de nodos y comunicación eficiente.
Casos reales en producción: Sherpa.ai ya trabaja con bancos, hospitales, Telcos y organismos públicos que están usando IA Federada para extraer valor del dato sin comprometer la privacidad.
La era de la anonimización como solución única está llegando a su fin. En un mundo donde la privacidad es una prioridad, donde las regulaciones son cada vez más exigentes y donde los datos distribuidos son la norma, el Aprendizaje Federado es la tecnología que marcará el futuro de la IA ética y segura.
Nuestra plataforma no solo lidera este cambio tecnológico, sino que ofrece a las organizaciones una vía concreta, escalable y legalmente sólida para innovar con datos sin comprometer lo más importante: la confianza de sus usuarios.