
En un mundo cada vez más impulsado por la inteligencia artificial y los datos, la privacidad se ha convertido en uno de los mayores retos tecnológicos, éticos y regulatorios. Empresas, gobiernos y organizaciones de todos los sectores buscan fórmulas para poder extraer valor de los datos sin poner en riesgo la confidencialidad de las personas o entidades implicadas.
Entre las múltiples aproximaciones que han surgido para abordar este dilema, destacan dos tecnologías en auge: los datos sintéticos y el Aprendizaje Federado (Federated Learning). Ambas persiguen el mismo objetivo —proteger la privacidad en entornos de IA—, pero lo hacen desde aproximaciones radicalmente distintas.
En Sherpa.ai, tras años de investigación y desarrollo en privacidad computacional, consideramos que el Aprendizaje Federado representa una solución más robusta, realista y escalable frente a los desafíos actuales. A continuación, analizamos por qué.
¿Qué son los datos sintéticos y por qué están ganando popularidad?
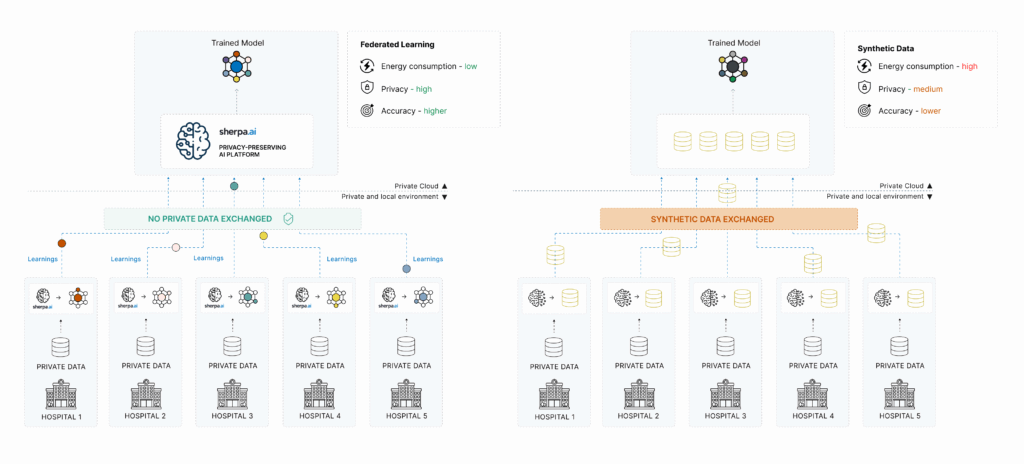
Los datos sintéticos son datos generados artificialmente mediante algoritmos que aprenden las características estadísticas de conjuntos de datos reales. Es decir, no corresponden a registros reales de personas, pero sí imitan su comportamiento y patrones.
Esta técnica se ha popularizado especialmente en sectores como la salud, los servicios financieros o el marketing, donde el acceso a datos reales está altamente restringido por regulaciones como el RGPD (Europa) o HIPAA (EE. UU.).
Ventajas iniciales de los datos sintéticos:
Evitan el uso directo de datos reales, reduciendo el riesgo legal.
Facilitan la colaboración y el intercambio de datos entre instituciones.
Aceleran el desarrollo de modelos de IA en entornos donde el acceso a datos está limitado.
Pero... ¿cuáles son sus límites?
A pesar de sus ventajas, los datos sintéticos presentan limitaciones estructurales que condicionan su efectividad:
No eliminan completamente los riesgos de privacidad: si el modelo generador no está bien protegido o si los datos reales son muy sensibles, puede haber filtraciones o reconstrucciones.
Modelos menos precisos: los datos sintéticos tienden a degradar la calidad del entrenamiento, sobre todo cuando los patrones reales son complejos o poco frecuentes.
No solucionan el problema de gobernanza: aunque no se comparta el dato real, sigue habiendo debate sobre quién puede acceder, usar y validar los datos sintéticos.
No sirven en tiempo real: la generación y validación de datos sintéticos requiere tiempo, lo que limita su aplicabilidad en casos donde se necesita IA sobre flujos de datos vivos (edge, IoT, ciberseguridad…).
Aprendizaje Federado: una solución desde el diseño
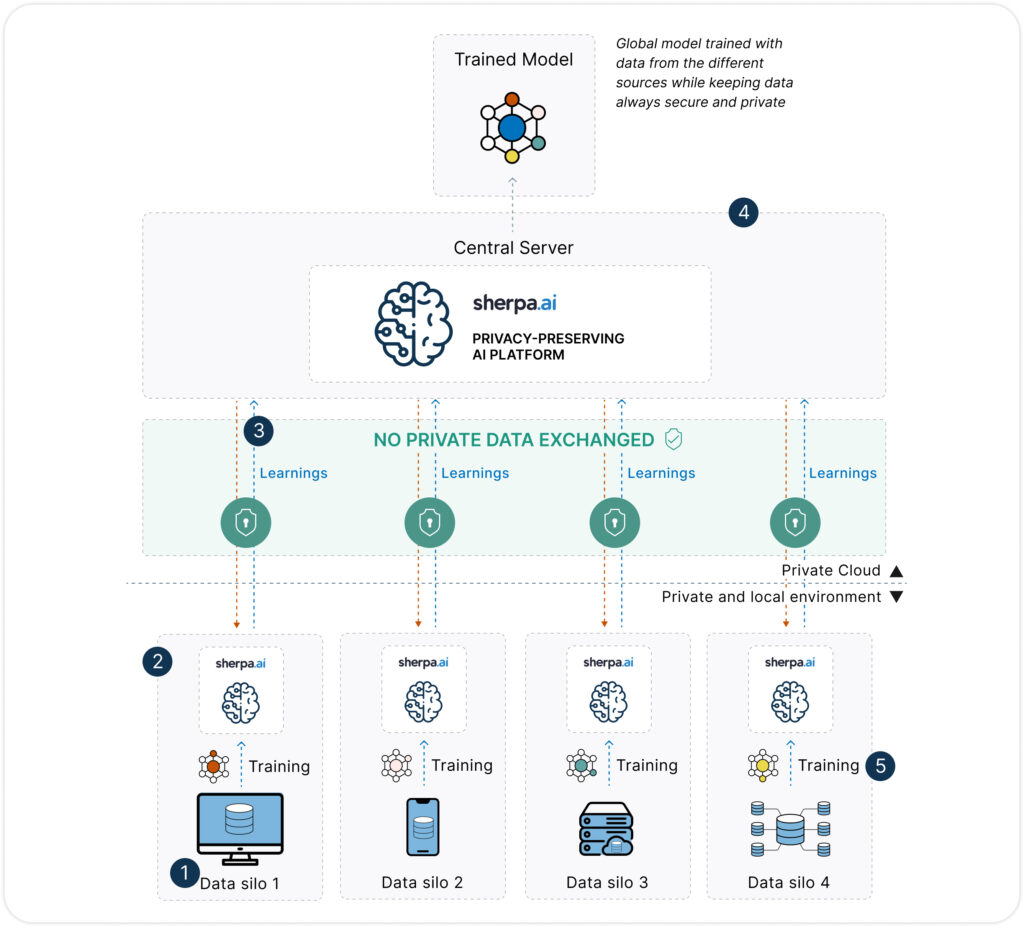
A diferencia de los datos sintéticos, el Aprendizaje Federado propone un cambio radical: en lugar de mover los datos al modelo, mueve el modelo a los datos. Esto permite que cada organización o dispositivo entrene localmente una copia del modelo sobre sus propios datos, compartiendo únicamente actualizaciones del modelo (no los datos en sí).
Beneficios clave del Aprendizaje Federado:
Privacidad real: los datos nunca abandonan su origen.
Cumplimiento por diseño con normativas de protección de datos.
Mayor fidelidad: se entrena directamente sobre los datos reales, sin necesidad de crear réplicas sintéticas.
Escalable y adaptable a múltiples entornos, incluyendo edge computing, dispositivos móviles, entornos hospitalarios, o plataformas soberanas de datos.
Si quieres aprender más sobre que es el Aprendizaje Federado, consulta aquí
Ventajas del Aprendizaje Federado frente a los datos sintéticos
| Categoría / Dimensión | Aprendizaje Federado | Datos Sintéticos |
|---|---|---|
| Privacidad | ||
| Privacidad y seguridad | ✅ Alta: los datos nunca se comparten. Solo se intercambian actualizaciones del modelo. | ⚠️ Limitada: los datos no son reales, pero el modelo generador puede filtrar patrones. |
| Anonimización previa (PII) | ✅ No necesaria: se entrena directamente en origen sin acceso al dato. | ❌ Requiere cuidados: el modelo generador se entrena con datos reales. |
| Cumplimiento normativo (GDPR) | ✅ Sólido: se alinea con GDPR, HIPAA, etc. al no mover datos personales. | ⚠️ Variable: si los datos sintéticos son demasiado parecidos, pueden violar la normativa. |
| Rendimiento | ||
| Transmisión de datos | ✅ No: los datos nunca abandonan su origen. | ❌ Sí: los datos sintéticos deben almacenarse, compartirse y gestionarse como nuevos datasets. |
| Consumo energético | ✅ Eficiente: sin necesidad de duplicación ni generación intermedia. | ⚠️ Medio-alto: el proceso de generación puede ser intensivo, especialmente con modelos generativos. |
| Calidad del modelo | ✅ Alta: se entrena con datos reales y actualizados. | ⚠️ Variable: puede degradarse si los datos sintéticos no representan bien la realidad. |
| Tiempos de entrenamiento | ✅ Razonables: entrenamiento local y paralelo por nodos. | ⏱️ Lento: el tiempo de generación + validación puede superar al del entrenamiento. |
| Otros | ||
| Coste de implementación | ✅ Bajo: sin duplicación de datos ni complejidad legal añadida. | ❌ Medio-alto: requiere herramientas de generación, validación y almacenamiento. |
| Escalabilidad | ✅ Alta: adaptable a dispositivos, edge, hospitales, banca, etc. | ⚠️ Limitada: generar datos sintéticos de calidad a gran escala requiere recursos. |
| Interpretabilidad y gobernanza | ✅ Alta: cada organización controla su nodo, sus datos y el modelo. | ⚠️ Ambigua: difícil auditar la trazabilidad de los datos generados y su uso posterior. |
¿Cumplen los datos sintéticos con el GDPR? No siempre.
Aunque a menudo se presentan como una solución “segura” y “legal” para evitar el uso de datos personales, los datos sintéticos no garantizan automáticamente el cumplimiento del Reglamento General de Protección de Datos (GDPR). Esta es una confusión común en el ámbito tecnológico y legal.
El GDPR no define ni regula explícitamente los datos sintéticos, pero establece que cualquier información que permita directa o indirectamente identificar a una persona física se considera dato personal. Por tanto, si el conjunto de datos sintéticos permite inferir o reconstruir información sobre individuos reales —algo que puede ocurrir si el modelo generador ha memorizado patrones sensibles—, esos datos seguirán estando sujetos a la normativa.
Principales riesgos legales asociados a los datos sintéticos:
Riesgo de reidentificación: Si el modelo generador fue entrenado con datos reales y no se aplicaron técnicas de regularización o privacidad diferencial, podría “memorizar” datos reales y devolverlos (incluso de forma parcial).
Dificultad para demostrar la anonimización: El GDPR exige que la anonimización sea irreversible. En muchos casos, no es posible demostrar con certeza que los datos sintéticos generados no puedan reidentificar a nadie.
Dudas en la trazabilidad: Una vez compartidos los datos sintéticos, puede ser difícil auditar su origen y garantizar que se generaron conforme a principios de licitud y minimización.
Problemas con el derecho al olvido: Si una persona solicita la supresión de sus datos personales, es prácticamente imposible eliminar su rastro si ha sido embebido estadísticamente en datos sintéticos generados previamente.
- Distribución estadística como forma de revelación: Aunque los datos se sinteticen o anonimicen, para que un modelo de IA pueda ejecutarse correctamente (fase de inferencia), los datos deben mantener una distribución estadística muy similar a los datos originales. Esta necesidad implica que parte de la información subyacente ya ha sido revelada o codificada en los datos sintéticos, lo cual puede tener implicaciones legales si esa distribución refleja patrones sensibles o identificables.
¿Por qué el Aprendizaje Federado es más adecuado?
El Aprendizaje Federado no necesita generar nuevos datos ni manipular los existentes. Simplemente permite entrenar modelos directamente donde residen los datos, sin necesidad de moverlos ni copiarlos. Esto reduce la superficie de riesgo legal y se alinea de forma natural con los principios del GDPR: minimización, propósito limitado, integridad, seguridad, trazabilidad y responsabilidad.
En lugar de intentar transformar los datos para que “dejen de ser personales”, como hace el enfoque sintético, el Aprendizaje Federado preserva la privacidad desde la arquitectura: el dato no se mueve, no se replica, no se transforma, y siempre permanece bajo el control de su propietario.
Casos de uso donde el Aprendizaje Federado supera a los datos sintéticos
Aunque los datos sintéticos pueden ser útiles en ciertos entornos de desarrollo o para compartir datasets de ejemplo, hay numerosos escenarios reales en los que el Aprendizaje Federado es claramente más eficaz, seguro y aplicable. Especialmente cuando hablamos de entornos regulados, datos en tiempo real o colaboración entre entidades.
1. Salud y hospitales
Problema: Los historiales clínicos contienen información extremadamente sensible. Compartirlos, incluso anonimizados o sintetizados, puede suponer un problema a nivel de regulación.
FL como solución: Permite entrenar modelos de diagnóstico, predicción de enfermedades o recomendación de tratamientos sin que los datos salgan de cada hospital.
✅ Privacidad garantizada, ✅ cumplimiento normativo, ✅ datos reales actualizados.
2. Banca y seguros
Problema: Las entidades financieras no pueden compartir información de clientes entre sí, y la generación de datos sintéticos puede alterar comportamientos reales de riesgo.
FL como solución: Permite a varios bancos colaborar en la detección de fraude o estimación de riesgo crediticio sin intercambiar bases de datos.
✅ Fidelidad de los modelos, ✅ protección del negocio, ✅ colaboración interbancaria segura.
3. Administraciones públicas y censos
Problema: La explotación de datos poblacionales, censales o fiscales plantea altos riesgos de privacidad.
FL como solución: Facilita entrenar modelos de planificación urbana, movilidad o políticas públicas respetando la soberanía de cada organismo o región.
✅ Descentralización, ✅ soberanía digital, ✅ transparencia.
4. Ciberseguridad colaborativa
Problema: Las empresas detectan amenazas distintas, pero no pueden compartir registros de tráfico, logs o patrones de ataque por riesgo legal o confidencialidad.
FL como solución: Permite entrenar modelos de detección de amenazas en los propios entornos de cada organización sin compartir datos brutos.
✅ Tiempo real, ✅ confidencialidad, ✅ inteligencia colectiva.
5. Industria y IoT
Problema: Los datos generados por sensores en fábricas o dispositivos conectados son masivos, heterogéneos y sensibles.
FL como solución: Posibilita el entrenamiento local de modelos de mantenimiento predictivo, optimización de procesos o análisis de fallos sin enviar datos al cloud.
✅ Baja latencia, ✅ eficiencia energética, ✅ operatividad en edge.
Sherpa.ai: la plataforma más avanzada de Aprendizaje Federado del mercado
En este contexto, Sherpa.ai ha desarrollado la plataforma de IA Federada más potente y completa de Europa, diseñada específicamente para resolver los retos de privacidad, seguridad y cumplimiento normativo en los sectores más exigentes.
¿Qué hace única a la plataforma de Sherpa.ai?
Privacidad diferencial integrada: no solo se entrena sin compartir datos, sino que además se aplican perturbaciones matemáticas para evitar la reconstrucción del dato a partir de los parámetros del modelo.
Control total por parte del cliente: los datos nunca salen del entorno del cliente. La plataforma puede desplegarse en sus instalaciones o en nube privada, garantizando la soberanía del dato.
Auditoría y trazabilidad: la solución incluye herramientas para registrar y demostrar que se cumple con el GDPR, la Ley de IA de la UE y otras normativas sectoriales.
Alta interoperabilidad y rendimiento: compatible con distintos frameworks de IA (TensorFlow, PyTorch, etc.), orquestación avanzada de nodos y comunicación eficiente.
Casos reales en producción: Sherpa.ai ya trabaja con bancos, hospitales, Telcos y organismos públicos que están usando IA Federada para extraer valor del dato sin comprometer la privacidad.
Conclusión
Los datos sintéticos pueden ser una herramienta útil en casos muy concretos, especialmente como sustituto temporal o para entornos de prueba. Sin embargo, no representan una solución integral al problema de la privacidad.
El Aprendizaje Federado, por el contrario, ofrece una arquitectura que respeta la soberanía del dato, potencia la inteligencia colectiva y cumple con la regulación desde su base. En un contexto donde la confianza es clave, esta aproximación no solo es más segura, sino también más eficaz y sostenible.
En Sherpa.ai creemos que la privacidad no debe ser un obstáculo para la innovación, sino su punto de partida. Por eso hemos hecho del Aprendizaje Federado el corazón de nuestra tecnología.