
Durante décadas, el desarrollo de la Inteligencia Artificial (IA) ha estado íntimamente ligado a la recopilación masiva de datos en servidores centralizados. Este enfoque ha permitido grandes avances, desde modelos de predicción hasta asistentes virtuales y sistemas de recomendación. Sin embargo, a medida que la sensibilidad de los datos ha aumentado —especialmente en sectores como la salud, las finanzas o la defensa—, también lo han hecho los riesgos asociados a su centralización.
Frente a este paradigma tradicional, el Aprendizaje Federado (Federated Learning) ha emergido como una solución que permite entrenar modelos de IA sin necesidad de mover los datos de su ubicación original. Este nuevo enfoque no solo mejora la privacidad, sino que también abre la puerta a una colaboración más segura entre organizaciones, cumpliendo con los marcos legales más estrictos.
En este artículo, comparamos en profundidad el enfoque clásico de datos centralizados con la propuesta disruptiva del Aprendizaje Federado, y analizamos sus ventajas, limitaciones y casos de uso más relevantes.
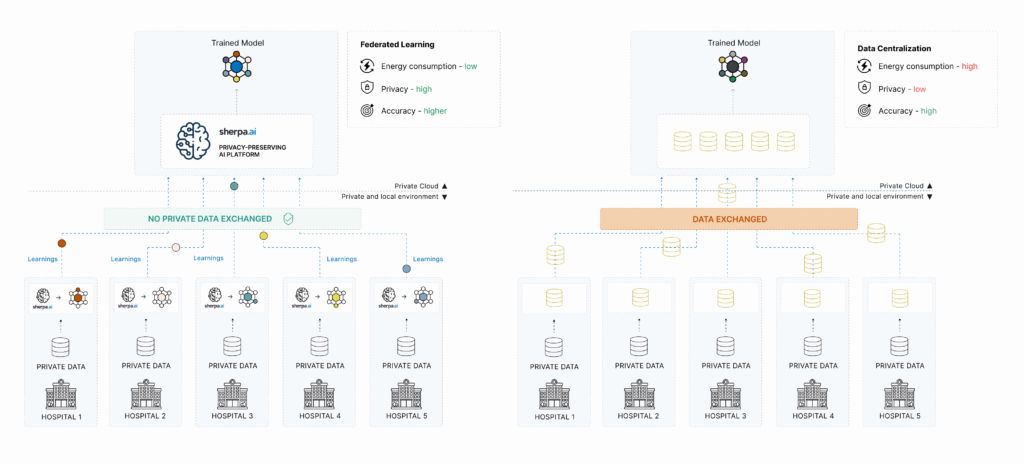
El enfoque tradicional: la centralización de datos
En el modelo tradicional de IA, los datos se recogen y se trasladan a un repositorio central —como un servidor, un centro de datos o una nube pública—, donde los modelos de aprendizaje automático son entrenados. Este proceso permite tener todos los datos disponibles en un solo lugar, lo cual facilita el desarrollo técnico y la optimización de los modelos.
Ventajas del enfoque centralizado:
Accesibilidad: Los científicos de datos pueden acceder a toda la información sin preocuparse por la fragmentación de las fuentes.
Simplicidad técnica: No requiere una arquitectura distribuida ni mecanismos de sincronización complejos.
Madurez del ecosistema: Existen herramientas consolidadas y procedimientos estandarizados para entrenar modelos en entornos centralizados.
Sin embargo, estas ventajas se ven eclipsadas por riesgos y limitaciones cada vez más relevantes:
Vulnerabilidades de seguridad: Reunir grandes volúmenes de datos en un único punto aumenta la superficie de ataque ante ciberamenazas.
Problemas de privacidad: En muchos casos, el traslado de datos implica la exposición de información personal o confidencial, lo que puede violar los derechos de los usuarios.
Cumplimiento normativo: Legislaciones como el Reglamento General de Protección de Datos (GDPR) en Europa, la Ley de Privacidad del Consumidor de California (CCPA) o la Ley de IA de la UE imponen restricciones estrictas sobre cómo se recogen, almacenan y procesan los datos.
Limitaciones logísticas: En entornos distribuidos, como hospitales, bancos o dispositivos IoT, mover todos los datos a un servidor central puede ser costoso, lento o incluso inviable.
Aprendizaje Federado: privacidad sin sacrificar inteligencia
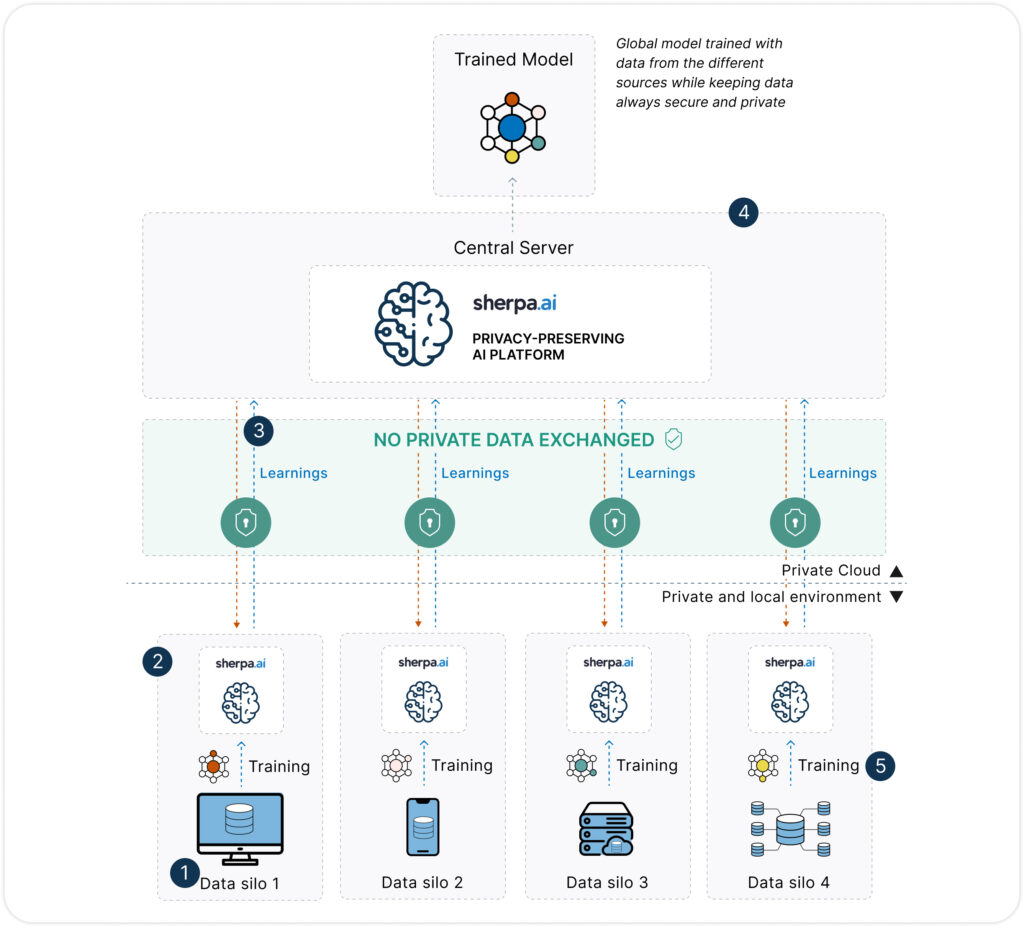
El Aprendizaje Federado propone un cambio de paradigma: en lugar de centralizar los datos, se entrena el modelo de forma distribuida, enviando algoritmos a los lugares donde los datos residen (dispositivos, servidores locales, nodos privados, etc.). Los modelos aprenden localmente, y solo se comparten actualizaciones (como gradientes o pesos) con un servidor central que las agrupa sin necesidad de acceder a los datos originales.
Beneficios clave del Aprendizaje Federado:
Privacidad por diseño: Los datos nunca salen de su fuente, lo que reduce drásticamente el riesgo de exposición.
Mayor cumplimiento legal: El enfoque facilita la adaptación a marcos regulatorios restrictivos, incluso en contextos internacionales.
Escalabilidad: Permite entrenar modelos en millones de dispositivos o sedes distribuidas sin necesidad de mover grandes volúmenes de datos.
Colaboración segura: Organizaciones competidoras (como bancos, aseguradoras u hospitales) pueden colaborar para entrenar modelos conjuntos sin compartir datos entre ellas.
Además, Sherpa.ai ha combinado el aprendizaje federado con tecnologías como:
Privacidad diferencial: Añade ruido estadístico para evitar la identificación de individuos.
Cifrado homomórfico: Permite realizar operaciones sobre datos cifrados.
Secure Multi-Party Computation (SMPC): Divide los datos y los procesa de forma conjunta sin que ninguna parte tenga acceso al conjunto completo.
Si quieres aprender más sobre que es el Aprendizaje Federado, consulta aquí
Comparativa directa: Aprendizaje Federado vs Datos Centralizados
A continuación, resumimos las principales diferencias entre ambos enfoques:
| Categoría | Aprendizaje Federado | Datos Centralizados |
|---|---|---|
| Privacidad | ||
| Privacidad y seguridad | ✅ Alta: los datos nunca abandonan su origen; solo se intercambian actualizaciones del modelo. | ❌ Baja: los datos se concentran en un único lugar, lo que los convierte en un objetivo valioso y más vulnerable. |
| Anonimización previa | ✅ No necesaria: el entrenamiento ocurre en el origen, reduciendo la necesidad de anonimización o preprocesamiento. | ❌ Necesaria: los datos sensibles deben ser tratados antes de ser centralizados, lo que añade complejidad. |
| Cumplimiento normativo | ✅ Sólido: al no mover datos personales, se facilita el cumplimiento de normativas como el GDPR o la HIPAA. | ❌ Complicado: trasladar, almacenar y procesar datos personales exige medidas legales y técnicas más estrictas. |
| Rendimiento | ||
| Transmisión de datos | ✅ Nula: solo se transmiten parámetros del modelo, nunca datos brutos. | ❌ Necesaria: los datos deben ser enviados al servidor central, lo que implica costes y riesgos. |
| Consumo energético | ✅ Eficiente: se evita la duplicación de datos y no se requiere una infraestructura centralizada intensiva. | ❌ Alto: se necesita gran capacidad de almacenamiento, transferencia y procesamiento en centros de datos. |
| Calidad del modelo | ✅ Alta: se entrena con datos reales, actualizados y en contexto. | ⚠️Alta: la centralización permite entrenar con todos los datos disponibles, pero a costa de privacidad. |
| Tiempo de entrenamiento | ✅ Eficiente: el entrenamiento distribuido en paralelo reduce tiempos y permite continuidad. | ❌ Variable: puede ser lento si la recopilación y procesamiento de datos son ineficientes. |
| Escalabilidad | ||
| Colaboración entre entidades | ✅ Segura: organizaciones pueden entrenar modelos conjuntos sin compartir datos sensibles. | ❌ Limitada: compartir datos entre instituciones suele implicar barreras legales, técnicas y de confianza. |
| Escalabilidad | ✅ Alta: se adapta fácilmente a entornos distribuidos (edge, hospitales, bancos, etc.). | ❌ Limitada: centralizar grandes volúmenes de datos se vuelve costoso y poco ágil a gran escala. |
| Latencia | ✅ Baja: el entrenamiento ocurre cerca del origen de los datos, lo que reduce la latencia. | ❌ Alta: mover datos a un servidor central introduce retardos y cuellos de botella. |
| Costes | ||
| Coste de implementación | ✅ Optimizado: se evita la duplicación de datos, los traslados masivos y parte de los requisitos legales. | ❌ Elevado: requiere infraestructura centralizada, almacenamiento masivo y medidas de cumplimiento costosas. |
| Mantenimiento y actualizaciones | ✅ Flexible: se pueden aplicar actualizaciones a nivel local sin interrumpir el sistema general. | ❌ Centralizado: las actualizaciones deben desplegarse desde el servidor, a menudo con riesgo de interrupciones. |
| Gobernanza | ||
| Soberanía de los datos | ✅ Preservada: cada entidad mantiene el control total sobre sus datos y sus nodos. | ❌ Reducida: al centralizar datos, se pierde claridad sobre su propiedad y control. |
| Auditabilidad y trazabilidad | ✅ Alta: los procesos de entrenamiento son controlados localmente y registrados por cada organización. | ❌ Débil: una vez integrados todos los datos, es difícil rastrear su origen o la evolución del modelo. |
¿Qué enfoque elegir?
a respuesta no es única ni definitiva. Ambos enfoques pueden ser válidos dependiendo del caso de uso, la arquitectura de datos existente, los requisitos legales y los objetivos de negocio.
Casos donde la centralización sigue siendo válida:
Proyectos de IA internos donde los datos ya están centralizados por diseño.
Casos donde la privacidad no es una preocupación crítica.
Escenarios con restricciones técnicas o presupuestarias para desplegar infraestructura federada.
Casos donde el Aprendizaje Federado es claramente superior:
Salud: Entrenar modelos predictivos sin sacar datos médicos de hospitales o clínicas.
Finanzas: Colaborar entre bancos o aseguradoras sin compartir transacciones individuales.
Defensa y seguridad: Extraer valor de datos sensibles sin comprometer soberanía ni confidencialidad.
IoT y edge computing: Entrenar modelos en dispositivos móviles, sensores o vehículos conectados.
Un cambio de paradigma en la IA
La pregunta ya no es si se pueden centralizar los datos, sino si debería hacerse. En un mundo donde la privacidad, la soberanía de los datos y la seguridad son prioridades crecientes, las organizaciones que lideren el cambio hacia modelos más éticos, sostenibles y colaborativos serán también las que lideren la nueva generación de IA.
Desde Sherpa.ai, apostamos firmemente por este cambio. Nuestra plataforma de Aprendizaje Federado permite a empresas e instituciones entrenar modelos de IA de forma segura, privada y eficiente, sin necesidad de compartir datos. Gracias a nuestra tecnología, sectores como la salud, la banca, la industria o la defensa ya están dando el salto hacia una inteligencia más responsable.
Sherpa.ai: la plataforma más avanzada de Aprendizaje Federado del mercado
En este contexto, Sherpa.ai ha desarrollado la plataforma de IA Federada más potente y completa de Europa, diseñada específicamente para resolver los retos de privacidad, seguridad y cumplimiento normativo en los sectores más exigentes.
¿Qué hace única a la plataforma de Sherpa.ai?
Privacidad diferencial integrada: no solo se entrena sin compartir datos, sino que además se aplican perturbaciones matemáticas para evitar la reconstrucción del dato a partir de los parámetros del modelo.
Control total por parte del cliente: los datos nunca salen del entorno del cliente. La plataforma puede desplegarse en sus instalaciones o en nube privada, garantizando la soberanía del dato.
Auditoría y trazabilidad: la solución incluye herramientas para registrar y demostrar que se cumple con el GDPR, la Ley de IA de la UE y otras normativas sectoriales.
Alta interoperabilidad y rendimiento: compatible con distintos frameworks de IA (TensorFlow, PyTorch, etc.), orquestación avanzada de nodos y comunicación eficiente.
Casos reales en producción: Sherpa.ai ya trabaja con bancos, hospitales, Telcos y organismos públicos que están usando IA Federada para extraer valor del dato sin comprometer la privacidad.
Conclusión
Durante mucho tiempo, se ha asumido que para construir modelos de IA precisos era necesario sacrificar la privacidad. El Aprendizaje Federado demuestra que esa dicotomía ya no es necesaria. Hoy, es posible construir modelos igual o más potentes, cumpliendo con las regulaciones y respetando la confidencialidad de los datos.
El futuro de la IA no será solo más inteligente, sino también más privado, ético y colaborativo.
Y ese futuro, empieza hoy.