
En el ámbito de la inteligencia artificial, contar con datos de calidad es esencial para entrenar modelos eficaces. En muchas ocasiones, los datos privados que se quieren usar para entrenar modelos de IA, están distribuidos en diferentes dispositivos, como teléfonos, sensores o servidores. Para entrenar modelos con dichos datos privados, se requiere recolectarlos en un solo lugar, lo que puede ser muy costoso, lento o incluso ilegal debido a regulaciones de privacidad, como las leyes de protección de datos.
Ante este problema existen diferentes aproximaciones, como la compartición de datos a través de técnicas de encriptación o anonimización, o generación de datos sintéticos. Todas ellas con un problema común, que los datos se comparten de alguna forma, lo cual presenta limitaciones debido a los requisitos legales y riesgos en cuanto a la seguridad y privacidad de los datos. Además, enviar datos constantemente a un servidor central requiere mucho ancho de banda y una gran infraestructura que puede acarrear grandes costes.
El aprendizaje federado es una solución innovadora que aborda el problema desde otra perspectiva. Permite aprovechar grandes cantidades de datos para entrenar modelos de IA con datos distribuidos en diferentes dispositivos sin comprometer la privacidad ni depender de una centralización masiva de información. El aprendizaje federado resuelve esto permitiendo que el entrenamiento ocurra localmente en cada dispositivo, compartiendo solo las actualizaciones del modelo y no los datos en sí. Siendo la única solución que permite entrenar modelos con datos en diferentes silos, sin compartirlos.
Esto supone un cambio de paradigma, puesto que, en vez de enviar los datos a un servidor central, enviamos el modelo al lugar donde están los datos. Evitando así el trasiego de datos y garantizando su privacidad y seguridad.
¿Qué es el Aprendizaje Federado?
El aprendizaje federado es un enfoque de Machine Learning distribuido que permite entrenar modelos de IA directamente en los dispositivos que contienen los datos, sin necesidad de trasladar los datos a un servidor central. Este proceso permite que los datos permanezcan localmente en sus orígenes, como teléfonos móviles, servidores privados o sistemas de empresas, y solo se envíen al servidor las actualizaciones de los parámetros del modelo.
Imaginemos que tenemos datos en varios dispositivos, como teléfonos o servidores, que queremos usar para entrenar a un modelo de IA. El enfoque tradicional requeriría enviar los datos a un servidor central para su procesamiento y entrenamiento. Lo cual no es posible en la mayoría de situaciones debido a limitaciones de privacidad o seguridad. Sin embargo, AF permite el uso de dichos datos para entrenar modelos, sin que estos se envíen. Como? Enviando el modelo que se quiere entrenar al lugar de origen de los datos, para que entrene de forma local con cada uno de ellos y únicamente compartan los parámetros de los modelos entrenados. Así, el modelo mejora colectivamente mientras la privacidad de los datos se mantiene protegida.
Este enfoque ofrece múltiples ventajas en comparación con otros métodos, especialmente cuando se priorizan aspectos como la privacidad de los datos, la reducción de costos de infraestructura y la mejora del rendimiento en entornos distribuidos.
A continuación mostramos un diagrama del funcionamiento de un proceso de entrenamiento a través de Aprendizaje Federado
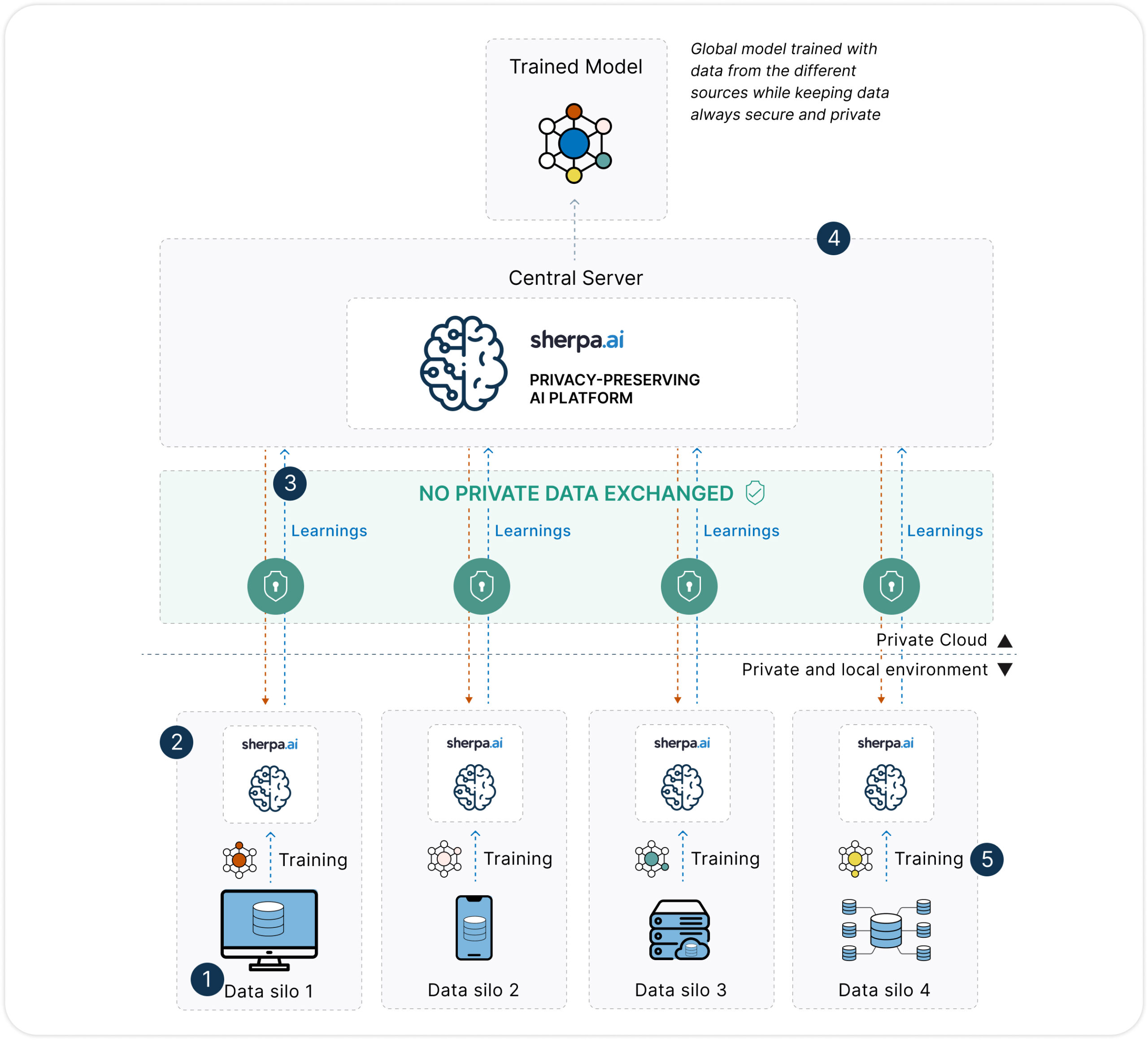
Proceso privado y seguro:
1. Los datos no pueden compartirse entre distintos silos.
2. El software se instala en el nodo (donde se encuentran los datos), permitiendo entrenar el modelo con datos locales sin compartirlos y garantizando que los datos no abandonen su servidor.
3. Sólo los modelos se intercambian. El servidor envía el modelo base y devuelve los aprendizajes generados en los nodos.
4. Los parámetros se agregan en la nube para generar el modelo global.
5. El modelo final se despliega de manera privada en cada uno de los nodos.
Arquitectura del Aprendizaje Federado
El entrenamiento federado involucra diversos elementos que permiten la colaboración entre múltiples dispositivos o entidades sin necesidad de compartir datos.
- Nodos: Son los dispositivos o servidores que poseen los datos y realizan el entrenamiento local del modelo de inteligencia artificial. Estos pueden ser cualquier tipo de servidor, ya sea on premise o cloud.
- Servidor Central: Funciona como el orquestador del proceso de aprendizaje federado. Se encarga de enviar los modelos a los Nodos y agregar los modelos que envían los Nodos después del entrenamiento local para generar el Modelo Global.
Como funciona el Aprendizaje Federado
- Inicialización del modelo: Se crea un modelo de IA base en un servidor central o en una arquitectura distribuida.
- Entrenamiento local: Los dispositivos o servidores locales reciben una copia del modelo y lo entrenan con sus propios datos.
- Envió de parámetros: En lugar de compartir los datos, los dispositivos envían las actualizaciones del modelo al servidor central.
- Agregación de parámetros: Se combinan las actualizaciones de los modelos recibidos de los distintos nodos y se genera el modelo global.
- Repetición del proceso: El modelo actualizado se redistribuye a los nodos locales para continuar el entrenamiento en iteraciones sucesivas.
Ventajas del Aprendizaje Federado
1. Uso de datos hasta ahora no disponibles
Resuelve el problema del acceso a datos de entrenamientos. Permite el uso de datos hasta ahora no accesibles por motivos de regulación, seguridad o de infraestructura, ya que los datos nunca se comparten.
2. Privacidad y cumplimiento normativo
No requiere compartición de datos y el almacenamiento centralizado, reduciendo riesgos de privacidad y seguridad, así como garantizando el cumplimiento normativo en sectores como salud, finanzas y el sector público.
3. Eficiencia de ancho de banda y recursos
Minimiza la transferencia de datos, reduciendo los recursos necesarios, los requisitos de ancho de banda y los costes operativos, especialmente en entornos con conectividad limitada. El entrenamiento descentralizado optimiza el uso de recursos locales y acelera el procesamiento sin depender de servidores externos.
4. Optimización de Modelos en Entornos Distribuidos
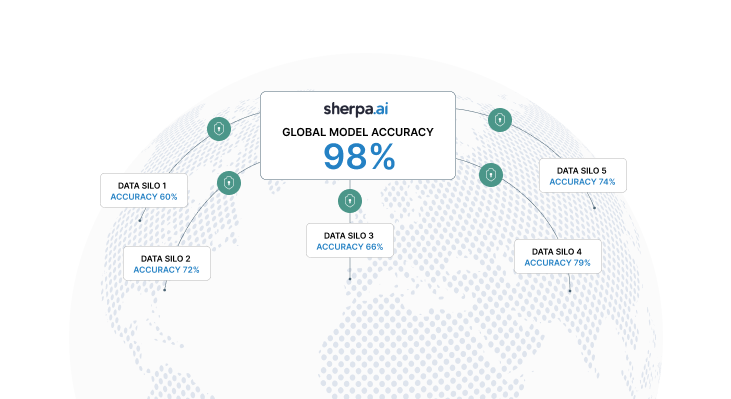
Al aprovechar datos de múltiples dispositivos o fuentes sin centralizarlos, el aprendizaje federado mejora la diversidad y precisión de los modelos. Además, permite la personalización por dispositivo o usuario sin perder la capacidad de aprendizaje global.
5. Escalabilidad y Flexibilidad
Aumenta la escalabilidad de los modelos sin necesidad de generar infraestructuras adicionales, ya que el entrenamiento ocurre en los propios dispositivos. Esto lo convierte en una solución ideal para negocios con datos en múltiples ubicaciones o que dependen de dispositivos móviles e IoT.
6. Implementación ágil de modelos
Los modelos pueden entrenarse y actualizarse en tiempo real directamente en los dispositivos, permitiendo una implementación rápida y adaptativa sin demoras por centralización de datos
Casos de uso habilitados por el Aprendizaje Federado
Sector Financiero
- Prevención del fraude – colaboración entre distintas entidades financieras.
- Reducción de churn y mejora de conversión – colaboración entre banca comercial y aseguradora.
- Cross-selling de productos – colaboración entre aseguradora y banca comercial
Salud y Biomedicina
- Diagnóstico y tratamiento personalizado – colaboración entre distintos hospitales (entidades de salud)
- Descubrimiento de nuevos fármacos – colaboración entre compañías farmacéuticas y entidades sanitarias
Industria y Manufactura
- Mantenimiento predictivo – colaboración entre distintos silos (ej. distintas fábricas)
- Optimización de procesos – colaboración entre distintas plantas de producción.
Telecomunicaciones
- Optimización de redes – colaboración entre distintas compañías de telecomunicaciones.
- Personalización de servicios – colaboración entre compañías de telecomunicaciones y terceras partes.
Ciberseguridad
- Detección de amenazas – colaboración entre distintos silos de datos
- Protección de datos sensibles – colaboración entre distintos silos de datos
Colaboraciones internas
- Mejora de modelos entre países – colaboración entre distintos países de una multinacional.
- Enriquecimiento entre distintos silos de datos – colaboración entre distintas áreas dentro de una compañía.
Conclusión
El aprendizaje federado está revolucionando la manera en que las empresas pueden utilizar los datos para entrenar modelos de inteligencia artificial, ofreciendo una solución escalable, eficiente y, lo más importante, respetuosa con la privacidad. El aprendizaje federado se destaca como la mejor solución en contextos donde la privacidad de los datos, la calidad del modelo y la eficiencia operativa son prioritarios. Con su capacidad para aprovechar datos distribuidos de manera segura y eficiente, el aprendizaje federado es, sin duda, el camino hacia el futuro de la inteligencia artificial. En este contexto, Sherpa.ai se posiciona como la plataforma más privada y segura del mercado, permitiendo a las empresas entrenar modelos avanzados sin comprometer la confidencialidad de su información.