
La economía actual se basa en los datos, pero el acceso a esos datos está cada vez más limitado por la regulación, la preocupación por la privacidad y la fragmentación tecnológica. ¿Cómo pueden colaborar diferentes organizaciones —como bancos, aseguradoras, operadores o instituciones públicas— sin comprometer la privacidad ni incumplir normativas como el RGPD o la futura Ley de IA europea?
Dos soluciones han emergido como alternativas viables: los Data Clean Rooms (DCR) y el Aprendizaje Federado (Federated Learning o FL). Ambos permiten a múltiples entidades colaborar en el análisis de datos o en el entrenamiento de modelos de IA sin compartir directamente los datos brutos.
Pero, aunque comparten objetivo, sus aproximaciones son muy diferentes. En este artículo, exploramos por qué el Aprendizaje Federado, tal y como lo implementa Sherpa.ai, representa una solución más segura, eficiente, escalable y sostenible que los Data Clean Rooms tradicionales.

¿Qué es un Data Clean Room?
Un Data Clean Room es un entorno seguro —generalmente en la nube— en el que diferentes entidades pueden cargar sus datos para realizar análisis conjuntos bajo condiciones controladas. Los DCR impiden el acceso directo entre las partes y permiten únicamente la ejecución de queries o la obtención de insights agregados previamente aprobados.
Este modelo se ha popularizado en sectores como la publicidad, los medios, el retail o la banca para realizar colaboraciones sin intercambiar datos identificables. Sin embargo, su arquitectura se basa en la centralización de los datos en un entorno común, lo que introduce retos técnicos, legales y de rendimiento.
Limitaciones clave de los Data Clean Rooms
Aunque los Data Clean Rooms representan un avance frente al intercambio directo de datos, su arquitectura centralizada y sus requisitos operativos implican una serie de limitaciones técnicas, legales y de eficiencia que deben tenerse en cuenta:
1. Dependencia de un entorno centralizado
Los DCR requieren que cada entidad participante cargue sus datos en una infraestructura común —generalmente gestionada por un proveedor externo— lo que implica:
Pérdida de soberanía sobre los datos,
Riesgo de exposición ante brechas de seguridad,
Dependencia técnica y contractual de un tercero.
2. Complejidad operativa y legal
Para colaborar en un DCR, las partes deben:
Establecer acuerdos legales específicos (DPA, contratos de uso, gobernanza compartida),
Validar cada análisis o modelo a ejecutar,
Coordinar flujos de datos, accesos y auditorías.
Esto ralentiza la colaboración, limita la agilidad y eleva los costes administrativos.
3. Baja escalabilidad técnica
En escenarios con múltiples entidades (por ejemplo, colaboraciones en red entre hospitales, bancos o universidades), los DCR escalan de forma limitada:
Requieren grandes capacidades de red y almacenamiento,
Su rendimiento disminuye con el número de participantes,
No están diseñados para entornos edge o distribuidos.
4. Limitaciones en la calidad del análisis
Por razones de seguridad o cumplimiento, muchas implementaciones de DCR:
Restringen los modelos a aplicar (solo modelos estadísticos o regresiones simples),
Limitan el acceso a datos altamente granulares,
No permiten entrenamiento de modelos complejos de IA sobre datos reales.
Esto puede traducirse en resultados menos precisos, menos personalizables y menos útiles.
5. Elevado consumo energético y duplicación de datos
Los DCR requieren:
Copiar y trasladar datasets completos a un entorno común,
Procesarlos múltiples veces,
Almacenarlos temporal o permanentemente.
Este modelo genera una huella energética considerable, y es especialmente ineficiente si se compara con modelos como el Aprendizaje Federado, que entrena directamente sobre el dato en su ubicación original.
¿Qué es el Aprendizaje Federado?
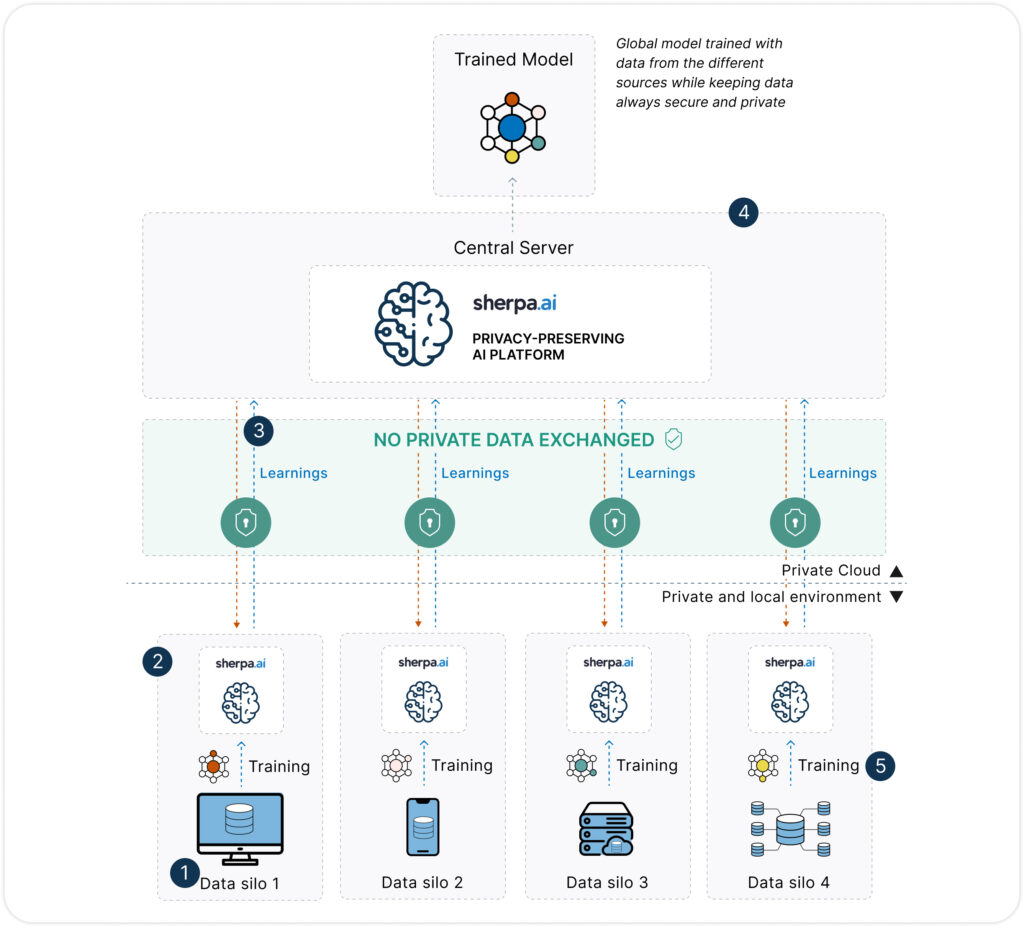
El Aprendizaje Federado (FL) es una técnica de entrenamiento de modelos de IA que permite construir modelos colaborativos sin necesidad de centralizar los datos. En lugar de mover los datos a un servidor central, el modelo se entrena localmente en cada nodo (hospital, banco, operador, etc.), y solo se comparten los parámetros del modelo —no los datos— con un servidor de coordinación.
La magia está en que los datos nunca abandonan su origen, lo cual cambia radicalmente el enfoque tradicional de la analítica.
Si quieres aprender más sobre que es el Aprendizaje Federado, consulta aquí
Federated Learning vs Data Clean Rooms
| Categoría | Federated Learning | Data Clean Rooms |
|---|---|---|
| Privacidad | ||
| Transferencia de datos | ✅ Los datos nunca abandonan su origen. | ❌ Requiere subir los datos a un entorno central. |
| Control del dato | ✅ Total: cada parte retiene soberanía sobre sus datos. | ⚠️ Limitado: el control se delega a un proveedor externo. |
| Cumplimiento RGPD | ✅ Alto: sin transmisión de datos personales. | ⚠️ Depende de la jurisdicción y configuración del entorno. |
| Privacidad diferencial integrada | ✅ Sí, incorporada por defecto. | ❌ No siempre disponible o aplicada. |
| Trazabilidad y auditoría | ✅ Completa: disponible dentro de Sherpa.ai. | ⚠️ Parcial o dependiente del proveedor. |
| Gobierno | ||
| Colaboración multilateral | ✅ Nativa: se pueden conectar múltiples partes sin confianza previa. | ⚠️ Requiere acuerdos complejos y confianza mutua. |
| Integración con sistemas existentes | ✅ Fácil: no requiere rediseño de arquitectura. | ⚠️ Requiere adaptar sistemas para integrarse con el entorno del DCR. |
| Rendimiento | ||
| Escalabilidad técnica | ✅ Alta: soporta edge, on-premise, cloud, y entornos híbridos. | ⚠️ Limitada: dependiente de infraestructura centralizada. |
| Velocidad y rendimiento | ✅ Paralelismo nativo y entrenamiento distribuido. | ❌ Lento: procesos legales, revisiones manuales y tiempos de acceso. |
| Calidad del modelo | ✅ Alta: entrena sobre datos reales sin pérdida de granularidad. | ⚠️ Limitada: suele restringirse a modelos simplificados o análisis agregados. |
| Otros | ||
| Coste de implementación | ✅ Eficiente: sin duplicación ni almacenamiento adicional. | ❌ Elevado: infraestructura compartida, validaciones, revisión legal. |
| Huella energética | ✅ Baja: procesamiento local y sin redundancia. | 🔋 Alta: requiere duplicar, mover y almacenar datos múltiples veces. |
Federated Learning vs Data Clean Rooms: implicaciones en el cumplimiento del RGPD
Data Clean Rooms: cumplimiento condicionado
Aunque los DCR están diseñados como entornos controlados, en la práctica requieren transferir datos personales —o pseudonimizados— a un entorno común gestionado por un tercero. Esto implica que:
Se necesita una base legal clara (consentimiento, interés legítimo o contrato),
El entorno debe ser auditable y localizado en jurisdicciones adecuadas (por ejemplo, dentro del EEE),
Las organizaciones siguen siendo responsables conjuntas del tratamiento de datos.
Además, el RGPD establece que si los datos pueden ser reidentificados con medios razonables, siguen considerándose datos personales, lo cual aplica a muchos datasets usados en Clean Rooms, incluso si han sido seudonimizados o agregados.
Federated Learning: cumplimiento nativo por diseño
El Aprendizaje Federado, en cambio, evita directamente la transferencia de datos personales. Los modelos se entrenan localmente, y solo se intercambian parámetros del modelo (como gradientes o pesos), que:
No contienen información identificable directamente,
Pueden ser protegidos adicionalmente con privacidad diferencial y agregación segura,
No permiten reconstruir el dataset original cuando se implementan correctamente.
Esto hace que el FL:
Reduzca significativamente el riesgo legal,
Se alinee con los principios de “privacidad desde el diseño”,
Elimine la necesidad de compartir datos personales entre entidades.
Además, cada organización conserva el rol de responsable del tratamiento, lo que simplifica los flujos de responsabilidad y las evaluaciones de impacto (DPIAs).
Comparativa de cumplimiento RGPD
| Criterio legal | Federated Learning | Data Clean Rooms |
|---|---|---|
| ¿Se transfieren datos personales? | ✅ No | ❌ Sí (aunque seudonimizados) |
| ¿Hay responsabilidad compartida? | ✅ No | ❌ Sí (joint controllers) |
| ¿Se cumple «privacy by design»? | ✅ Nativamente | ⚠️ Depende de la configuración |
| ¿Se puede evitar consentimiento? | ✅ En muchos casos (interés legítimo + FL) | ⚠️ No siempre (requiere base legal clara) |
| ¿Es necesario almacenar los datos? | ✅ No | ❌ Sí, en entorno común |
| ¿Alineado con el AI Act? | ✅ Sí, favorecido explícitamente | ⚠️ En revisión (no está garantizado) |
Casos de uso reales donde el Aprendizaje Federado supera a los Data Clean Rooms
Aunque los Data Clean Rooms han ganado popularidad en sectores como el marketing digital, existen numerosos escenarios reales en los que el Aprendizaje Federado es claramente superior, especialmente cuando la privacidad, la precisión y la flexibilidad son fundamentales. A continuación, destacamos algunos ejemplos representativos:
1. Colaboración entre hospitales para diagnóstico médico
El reto: Varias instituciones sanitarias desean colaborar para entrenar un modelo de IA que ayude a diagnosticar enfermedades raras a partir de imágenes médicas. Sin embargo, los datos clínicos son extremadamente sensibles y están protegidos por leyes como la GDPR o HIPAA.
¿Por qué no DCR?
Cargar imágenes médicas anonimizadas en un entorno compartido no solo requiere un proceso legal complejo, sino que además reduce la calidad diagnóstica, ya que el anonimizado elimina metadatos clínicos relevantes.
¿Por qué sí FL?
Con Aprendizaje Federado, cada hospital entrena localmente sobre sus imágenes originales, manteniendo la fidelidad del dato y la privacidad. Sherpa.ai garantiza que ningún dato personal abandone el entorno hospitalario, cumpliendo de forma nativa con la legislación.
2. Prevención de fraude entre bancos competidores
El reto: Varias entidades financieras quieren detectar patrones de fraude que cruzan múltiples instituciones (por ejemplo, tarjetas clonadas que se usan en diferentes bancos).
¿Por qué no DCR?
Un Data Clean Room requeriría que los bancos compartan sus datos de transacciones en un entorno común, lo que es legal y operativamente inviable debido a la competencia y a la confidencialidad del dato financiero.
¿Por qué sí FL?
Con FL, cada banco entrena el modelo con sus propias transacciones, sin compartir datos con sus competidores. El modelo aprende a detectar fraudes complejos sin comprometer la privacidad ni el secreto bancario. Además, se evita toda fricción legal entre entidades.
3. Optimización de campañas conjuntas entre telcos y terceros (retail, aerolíneas…)
El reto: Una operadora móvil desea colaborar con una aerolínea y una cadena de retail para ofrecer promociones personalizadas a usuarios frecuentes. Cada empresa dispone de información valiosa, pero fragmentada.
¿Por qué no DCR?
El uso de un DCR entre tres entidades diferentes requiere un alto grado de confianza y acuerdos legales multilaterales complejos, además de procesos de estandarización de datos y auditoría.
¿Por qué sí FL?
El Aprendizaje Federado permite que cada parte entrene localmente con su propia información, contribuyendo a un modelo compartido sin revelar datos a los demás. Esto hace viable la personalización a gran escala sin fricciones ni exposición legal.
4. Mantenimiento predictivo en redes industriales multisector
El reto: Fabricantes de componentes industriales quieren colaborar para anticipar fallos en equipos distribuidos globalmente. Cada empresa recoge datos de sensores en condiciones de operación reales.
¿Por qué no DCR?
Centralizar estos datos en un Data Clean Room supondría mover grandes volúmenes de información desde fábricas o dispositivos edge, con costes elevados y baja viabilidad técnica.
¿Por qué sí FL?
El FL puede ejecutarse directamente sobre los dispositivos o en gateways locales, entrenando modelos en entornos industriales sin mover los datos. Es más eficiente, más seguro y mucho más escalable que un enfoque centralizado.
Sherpa.ai: la plataforma más avanzada de Aprendizaje Federado del mercado
En este contexto, Sherpa.ai ha desarrollado la plataforma de IA Federada más potente y completa de Europa, diseñada específicamente para resolver los retos de privacidad, seguridad y cumplimiento normativo en los sectores más exigentes.
¿Qué hace única a la plataforma de Sherpa.ai?
Privacidad diferencial integrada: no solo se entrena sin compartir datos, sino que además se aplican perturbaciones matemáticas para evitar la reconstrucción del dato a partir de los parámetros del modelo.
Control total por parte del cliente: los datos nunca salen del entorno del cliente. La plataforma puede desplegarse en sus instalaciones o en nube privada, garantizando la soberanía del dato.
Auditoría y trazabilidad: la solución incluye herramientas para registrar y demostrar que se cumple con el GDPR, la Ley de IA de la UE y otras normativas sectoriales.
Alta interoperabilidad y rendimiento: compatible con distintos frameworks de IA (TensorFlow, PyTorch, etc.), orquestación avanzada de nodos y comunicación eficiente.
Casos reales en producción: Sherpa.ai ya trabaja con bancos, hospitales, Telcos y organismos públicos que están usando IA Federada para extraer valor del dato sin comprometer la privacidad.
Conclusión
Los Data Clean Rooms han supuesto un avance importante en la colaboración basada en datos, especialmente en sectores como la publicidad o el marketing. Pero su enfoque centralizado, su complejidad operativa y sus limitaciones técnicas los hacen insuficientes para escenarios donde la privacidad, la escalabilidad y la precisión son críticas.
El Aprendizaje Federado, tal y como lo implementa Sherpa.ai, ofrece una alternativa más robusta, segura y sostenible. Una tecnología capaz de habilitar la colaboración sin compartir datos, de forma escalable, auditable y compatible con las regulaciones más exigentes.
En el nuevo paradigma de la IA responsable, la privacidad no es una barrera, es una ventaja competitiva.