Introducción
El crecimiento del uso de datos en la inteligencia artificial (IA) ha impulsado la necesidad de desarrollar métodos para proteger la privacidad de la información sin comprometer su utilidad. Dos de las estrategias más utilizadas para este propósito son la anonimización de datos y el aprendizaje federado (Federated Learning, FL).
Si bien ambas técnicas buscan garantizar la privacidad de los datos, presentan diferencias fundamentales en términos de seguridad, eficiencia y cumplimiento normativo.
En este artículo, exploramos cómo funcionan estas dos estrategias, sus diferencias clave y por qué el aprendizaje federado suele ser una mejor opción para preservar la privacidad sin sacrificar el valor de los datos.
¿Qué es la Anonimización de Datos?
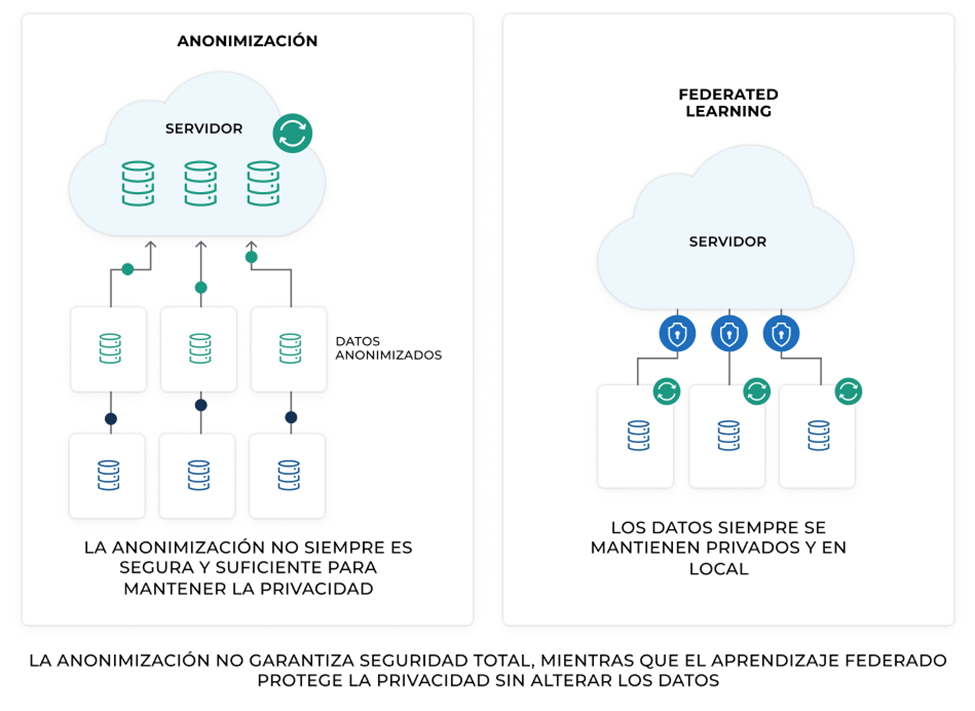
La anonimización es un proceso que modifica los datos personales para evitar la identificación de individuos. Su objetivo es permitir el uso y análisis de información sin comprometer la privacidad de los usuarios.
Cómo funciona la Anonimización de Datos
- Eliminación o modificación de identificadores personales: Se eliminan datos como nombres, direcciones, teléfonos o cualquier otra información que pueda vincularse directamente con una persona.
- Técnicas de enmascaramiento: Métodos como la agregación, la generalización o la aleatorización se aplican para reducir la posibilidad de reidentificación.
- Generación de datos sintéticos: En algunos casos, se crean conjuntos de datos artificiales que mantienen características estadísticas similares a los originales sin contener información real.
Beneficios de la Anonimización de Datos
- Cumplimiento con regulaciones de privacidad: Cumple con normativas como el GDPR y la CCPA al reducir el riesgo de exposición de datos personales.
- Facilita el intercambio de información: Permite compartir datos sin revelar información sensible.
- Reducción de riesgos legales y de seguridad: Minimiza la posibilidad de filtraciones de datos personales.
Sin embargo, la anonimización tiene importantes limitaciones. Uno de sus principales problemas es que los datos anonimizados pueden ser reidentificados mediante técnicas avanzadas de correlación o aprendizaje automático, especialmente si se combinan con otros conjuntos de datos disponibles públicamente.
¿Qué es el Aprendizaje Federado?
El Aprendizaje Federado (FL) es un método de IA que permite entrenar modelos sin necesidad de transferir datos a un servidor central. En lugar de recopilar información en una base de datos única, FL permite que los modelos se entrenen en los dispositivos o servidores donde los datos residen, asegurando que la información nunca salga de su origen.
Cómo funciona el Aprendizaje Federado
- Distribución del modelo: Se envía un modelo inicial a los dispositivos o servidores con datos locales.
- Entrenamiento en el dispositivo: Cada nodo entrena el modelo con sus propios datos sin compartirlos.
- Envío de parámetros actualizados: Solo se envían actualizaciones del modelo, no los datos en sí.
- Agregación global: Un servidor central combina las actualizaciones para mejorar el modelo global sin acceder a la información original.
Beneficios del Aprendizaje Federado
- Privacidad mejorada: Los datos permanecen en su lugar de origen, reduciendo el riesgo de filtraciones.
- Mayor precisión y utilidad: A diferencia de la anonimización, no se pierde información relevante en el proceso.
- Cumplimiento normativo: Facilita el cumplimiento de regulaciones al evitar la necesidad de centralizar datos personales.
- Eficiencia computacional: Reduce la transferencia de datos, optimizando el ancho de banda y el almacenamiento.
Comparación entre Aprendizaje Federado y Anonimización de Datos:
| Característica | Aprendizaje Federado (FL) | Anonimización de Datos |
| Privacidad de datos | Los datos nunca salen de su origen. | Los datos se modifican para ocultar información personal. |
| Eficiencia en el análisis | Mantiene la integridad de los datos y permite entrenar modelos de IA sin pérdida de información. | Puede afectar la calidad de los datos y reducir su utilidad. |
| Riesgo de reidentificación | Muy bajo, ya que los datos no se comparten ni se transfieren. | Alto, ya que los datos pueden ser correlacionados con otras fuentes. |
| Cumplimiento normativo | Facilita el cumplimiento del GDPR, HIPAA, etc. | Puede cumplir regulaciones, pero el riesgo de reidentificación puede generar problemas legales. |
| Escalabilidad y aplicabilidad | Altamente escalable para múltiples industrias (salud, finanzas, telecomunicaciones, etc.). | Limitado a casos donde la pérdida de precisión no sea un problema crítico. |
| Seguridad de los datos | Mayor seguridad al no exponer los datos a terceros. | Puede ser vulnerable a ataques de reidentificación. |
Ventajas del Aprendizaje Federado frente a la Anonimización de Datos
Aunque la anonimización de datos ha sido una solución tradicional para proteger la privacidad, el aprendizaje federado ofrece ventajas significativas en términos de seguridad, precisión y escalabilidad:
- Menor riesgo de reidentificación:
- Los datos nunca abandonan su fuente original, lo que evita la exposición a ataques externos.
- La anonimización, en cambio, puede ser vulnerable a técnicas de correlación y ataques de inferencia.
- Mayor precisión y calidad de los datos:
- La anonimización puede distorsionar la información, reduciendo la efectividad de los modelos de IA.
- Con el aprendizaje federado, los datos permanecen en su formato original, garantizando modelos más precisos y robustos.
- Cumplimiento normativo simplificado:
- FL facilita la adhesión a normativas como GDPR e HIPAA al evitar la transferencia de datos sensibles.
- La anonimización puede ser cuestionable si los datos pueden ser reidentificados.
- Escalabilidad y adaptabilidad:
- FL es ideal para entornos distribuidos como bancos, hospitales y dispositivos IoT, donde los datos se encuentran dispersos.
- La anonimización requiere procesos adicionales antes de compartir datos, lo que puede ser costoso y difícil de implementar a gran escala.
Conclusión
La privacidad de los datos es un desafío clave en la era de la inteligencia artificial. Si bien la anonimización ha sido un enfoque tradicional, sus limitaciones en seguridad, precisión y cumplimiento normativo la hacen insuficiente en muchos casos.
El aprendizaje federado surge como una alternativa más segura y eficiente, ya que permite entrenar modelos de IA sin compartir datos sensibles, reduciendo los riesgos de filtración y mejorando la precisión del análisis.
Para empresas en sectores como salud, banca, seguros y telecomunicaciones, FL no solo protege la privacidad, sino que también permite aprovechar todo el potencial de los datos sin comprometer la seguridad ni la regulación.
El futuro de la IA depende de métodos que equilibren privacidad y rendimiento, y el aprendizaje federado está demostrando ser una de las soluciones más prometedoras para lograrlo.