Introducción
El crecimiento de la inteligencia artificial (IA) y el análisis de datos ha llevado a las empresas a considerar cuál es la mejor forma de gestionar y procesar la información. Tradicionalmente, el enfoque más utilizado ha sido la centralización de datos, donde toda la información se recopila y almacena en servidores o centros de datos centralizados para su procesamiento.
Sin embargo, con el aumento de las preocupaciones sobre la privacidad, la seguridad y el cumplimiento normativo, ha surgido el aprendizaje federado (Federated Learning, FL) como una alternativa innovadora.
En este artículo, exploramos las diferencias entre ambos enfoques, sus ventajas y desventajas, y por qué el aprendizaje federado está emergiendo como una solución clave para el futuro de la IA.
¿Qué es la Centralización de Datos?
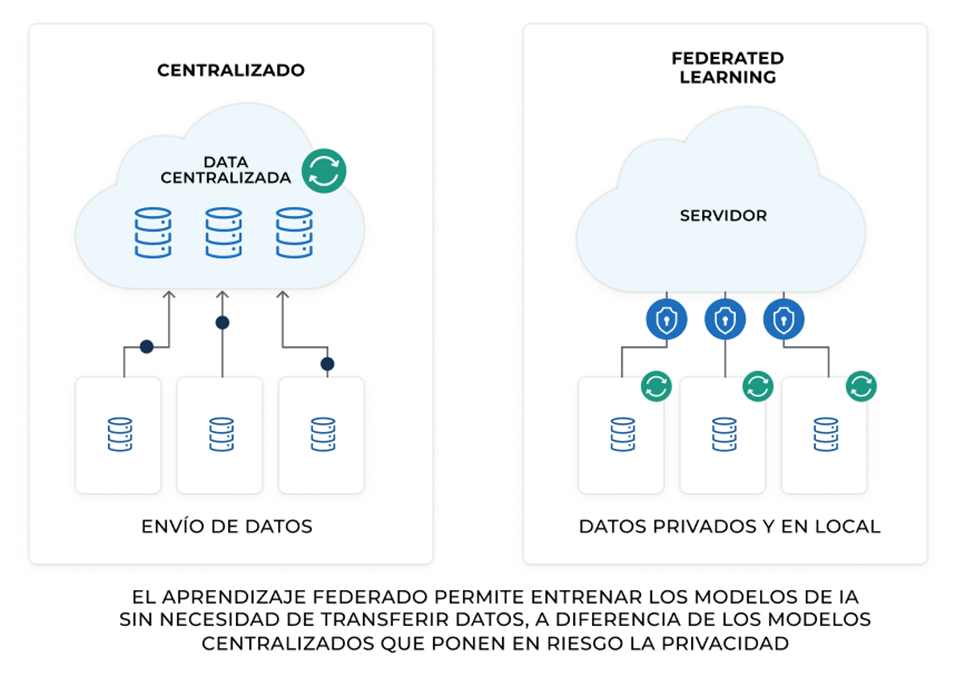
La centralización de datos es el proceso de recopilar información de múltiples fuentes y almacenarla en un único repositorio, como un centro de datos o una nube centralizada. Este modelo ha sido la base de la mayoría de las estrategias de IA y análisis de datos durante años.
Cómo funciona la Centralización de Datos
- Recopilación de datos: Se extraen datos de dispositivos, usuarios o entidades distribuidas.
- Transferencia a un servidor central: Los datos se envían a una ubicación única para su procesamiento.
- Almacenamiento y procesamiento: La información es limpiada, estructurada y utilizada para entrenar modelos de IA o realizar análisis.
- Distribución de resultados: Una vez generado el modelo, este puede ser aplicado en diferentes dispositivos o sistemas.
Beneficios de la Centralización de Datos
- Fácil gestión y acceso: Tener todos los datos en un solo lugar simplifica la administración y el procesamiento.
- Mayor capacidad de cómputo: Los centros de datos pueden utilizar hardware especializado para entrenar modelos complejos.
- Integración con herramientas existentes: Se adapta a la mayoría de las arquitecturas tradicionales de IA y análisis.
Sin embargo, la centralización de datos presenta importantes desafíos, especialmente en términos de privacidad, seguridad y escalabilidad.
Limitaciones de la Centralización de Datos
- Riesgos de seguridad: Al concentrar todos los datos en un solo lugar, un ataque o filtración puede comprometer grandes volúmenes de información.
- Problemas de privacidad y cumplimiento normativo: Cumplir con regulaciones como GDPR o HIPAA es más complejo cuando los datos deben ser transferidos y almacenados en servidores externos.
- Costes elevados: Almacenamiento, transferencia y procesamiento de grandes volúmenes de datos requieren una infraestructura costosa.
- Latencia y eficiencia: Transferir datos desde múltiples dispositivos a un servidor central puede generar retrasos y un uso ineficiente del ancho de banda.
¿Qué es el Aprendizaje Federado?
El Aprendizaje Federado (FL) es una metodología de IA que permite entrenar modelos sin necesidad de transferir datos a un servidor central. En su lugar, los datos permanecen en sus dispositivos de origen y solo se envían actualizaciones del modelo.
Cómo funciona el Aprendizaje Federado
- Distribución del modelo: Se envía un modelo inicial a cada dispositivo o nodo con datos locales.
- Entrenamiento local: Cada nodo entrena el modelo de manera descentralizada con sus propios datos.
- Compartición de actualizaciones: En lugar de compartir datos, solo se envían parámetros y ajustes del modelo.
- Agregación de resultados: Un servidor central combina las actualizaciones de múltiples nodos para mejorar el modelo global sin acceder a los datos originales.
Beneficios del Aprendizaje Federado
- Mayor privacidad: Los datos nunca abandonan su origen, reduciendo el riesgo de filtraciones.
- Cumplimiento normativo simplificado: Facilita la conformidad con regulaciones de protección de datos.
- Reducción del consumo de ancho de banda: Solo se transmiten actualizaciones del modelo, no datos brutos.
- Escalabilidad: Puede ser implementado en múltiples dispositivos y entornos sin necesidad de grandes centros de datos.
Comparación entre Aprendizaje Federado y Centralización de Datos
| Característica | Aprendizaje Federado (FL) | Centralización de Datos |
| Privacidad de datos | Los datos permanecen en su origen. | Los datos se transfieren a un servidor central. |
| Seguridad | Minimiza el riesgo de filtraciones. | Alto riesgo en caso de ciberataques. |
| Cumplimiento regulatorio | Más sencillo cumplir GDPR, HIPAA, etc. | Requiere medidas adicionales para cumplir normativas. |
| Eficiencia de ancho de banda | Se envían solo actualizaciones del modelo. | Requiere transferencia de grandes volúmenes de datos. |
| Latencia y procesamiento | Procesamiento distribuido más rápido. | Puede generar latencias en la transferencia de datos. |
| Escalabilidad | Fácilmente adaptable a múltiples dispositivos. | Requiere una infraestructura centralizada robusta. |
| Coste de infraestructura | Reduce costes de almacenamiento y cómputo. | Altos costes de servidores y almacenamiento. |
Ventajas del Aprendizaje Federado frente a la Centralización de Datos
El aprendizaje federado ofrece múltiples ventajas sobre la centralización de datos, especialmente en entornos donde la privacidad y la eficiencia son críticas.
- Mayor protección de la privacidad
- FL permite entrenar modelos sin necesidad de compartir datos personales, evitando riesgos de exposición.
- La centralización implica transferir datos sensibles, lo que aumenta la vulnerabilidad ante ataques o filtraciones.
- Cumplimiento normativo más sencillo
- Las regulaciones de privacidad como GDPR y CCPA exigen que los datos se procesen de forma segura y con consentimiento explícito.
- Con FL, las empresas pueden evitar la necesidad de almacenar datos sensibles en servidores centralizados.
- Menor coste y mayor eficiencia operativa
- FL reduce el consumo de ancho de banda al enviar solo parámetros del modelo en lugar de datos completos.
- La centralización requiere infraestructura de almacenamiento y procesamiento costosa.
- Escalabilidad y adaptabilidad
- FL es ideal para entornos distribuidos como dispositivos móviles, hospitales, bancos y redes IoT.
- La centralización puede ser ineficiente cuando los datos provienen de múltiples ubicaciones y dispositivos.
Conclusión
Si bien la centralización de datos ha sido el estándar tradicional para entrenar modelos de IA, su eficacia se ve limitada por preocupaciones de privacidad, seguridad, costes y escalabilidad.
El aprendizaje federado surge como una solución innovadora que permite entrenar modelos de IA sin comprometer la privacidad de los datos ni generar grandes costes de infraestructura.
Para sectores como salud, banca, telecomunicaciones y defensa, donde la privacidad y la eficiencia son clave, el aprendizaje federado ofrece una alternativa segura y eficaz para aprovechar el potencial de la inteligencia artificial sin los riesgos asociados a la centralización de datos.
La IA del futuro debe equilibrar rendimiento y privacidad, y el aprendizaje federado se está posicionando como la mejor estrategia para lograrlo.