
El Aprendizaje Federado se ha consolidado como una de las tecnologías más prometedoras para entrenar modelos de inteligencia artificial sin necesidad de centralizar los datos. Gracias a su capacidad para preservar la privacidad y cumplir regulaciones como el RGPD, es cada vez más adoptado en sectores como salud, banca, energía o defensa. Pero dentro del Aprendizaje Federado existen distintos enfoques técnicos que se adaptan a las características del dato y la problemática concreta.
En este artículo nos hemos centrado en los dos tipos más extendidos de Aprendizaje Federado: Horizontal y Vertical, ya que son los pilares de la mayoría de aplicaciones actuales. Sin embargo, existen otros paradigmas como el Aprendizaje Federado Transferido, el Cross-silo FL o combinaciones con técnicas criptográficas avanzadas. Estos enfoques permiten abordar escenarios aún más complejos y serán tratados en profundidad en futuros artículos del blog.
Antes de entrar en las diferencias, recordemos brevemente en qué consiste. El Aprendizaje Federado permite entrenar modelos de IA sin mover los datos de su origen. En lugar de centralizar la información en un único servidor, el modelo se entrena localmente en cada nodo (por ejemplo, en hospitales o bancos), y sólo se comparten parámetros del modelo —no datos— con un servidor central que los agrega de forma segura.
Esto permite cumplir normativas de privacidad, reducir el riesgo de filtraciones y habilitar colaboraciones entre organizaciones que antes eran impensables por restricciones legales o de competencia.
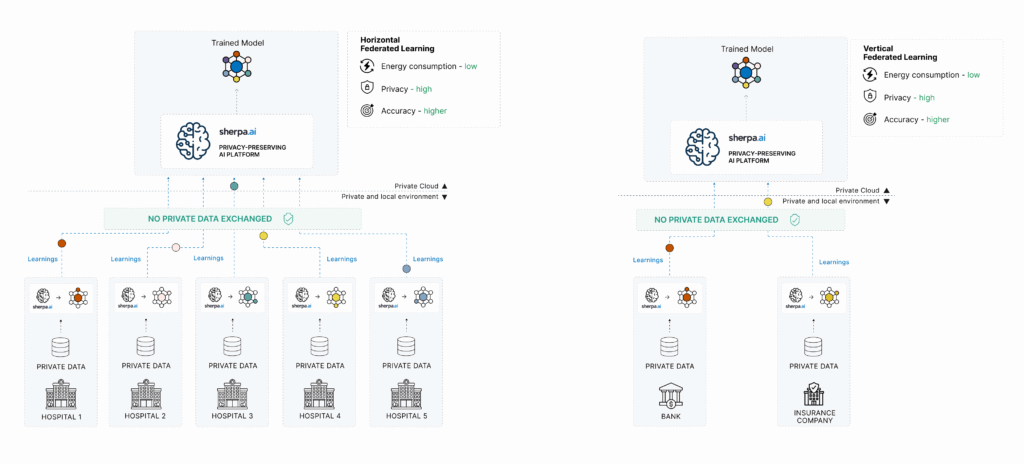
Aprendizaje Federado Horizontal (HFL)
El Aprendizaje Federado Horizontal se da cuando varias entidades tienen conjuntos de datos con las mismas características (features), pero sobre diferentes individuos (samples).
Ejemplo:
Imaginemos tres hospitales en diferentes regiones. Todos registran los mismos campos para sus pacientes: edad, presión arterial, nivel de glucosa, diagnóstico, etc. Pero cada uno tiene pacientes diferentes. En este caso, es ideal aplicar Aprendizaje Federado Horizontal: cada hospital entrena el modelo localmente sobre sus pacientes y se comparten solo los parámetros del modelo con un servidor que los agrega para mejorar el modelo global.
Casos de uso:
Colaboración entre hospitales para mejorar el diagnóstico de enfermedades raras.
Empresas de telecomunicaciones que entrenan modelos de predicción de abandono (churn) sin compartir bases de datos de clientes.
Sistemas de recomendación entre filiales de un grupo internacional con usuarios distintos pero productos comunes.
Aprendizaje Federado Vertical (VFL)
El Aprendizaje Federado Vertical se da cuando distintas organizaciones tienen información de los mismos individuos, pero con diferentes atributos (features).
Ejemplo:
Un banco y una aseguradora comparten muchos clientes. El banco tiene datos financieros: ingresos, gastos, historial crediticio. La aseguradora tiene datos de salud y seguros contratados. Ninguna entidad puede compartir los datos por separado, pero juntas podrían construir un modelo predictivo mucho más robusto. El Aprendizaje Federado Vertical permite entrenar modelos combinando esta información sin que ninguna parte acceda a los datos de la otra.
Casos de uso:
Modelos de scoring crediticio entre bancos y fintechs.
Predicción de fraude entre instituciones financieras y operadores de telecomunicaciones.
Marketing personalizado entre empresas con bases de datos complementarias de un mismo cliente
¿Qué enfoque es mejor?
Depende del caso. Ambos enfoques permiten entrenar modelos sin comprometer la privacidad, pero cada uno se adapta a una situación distinta:
| Tipo de FL | Mismo conjunto de atributos | Mismo conjunto de individuos | Ejemplo típico |
|---|---|---|---|
| Horizontal | ✅ | ❌ | Hospitales con pacientes diferentes |
| Vertical | ❌ | ✅ | Banco y aseguradora con clientes comunes |
Además, existen casos más complejos, como el Aprendizaje Federado Transversal o Transfer Learning Federado, que combinan ambos enfoques o permiten transferir conocimiento entre dominios distintos. Pero HFL y VFL siguen siendo los pilares básicos en la mayoría de aplicaciones reales.
Ventajas frente a otras soluciones de privacidad
Aunque existen otras tecnologías para entrenar IA de forma segura, como los Datos Sintéticos, el Cifrado Homomórfico o los Entornos Seguros de Ejecución (TEE), el Aprendizaje Federado ofrece una combinación única de ventajas:
Privacidad real desde el diseño: los datos nunca abandonan su origen.
Cumplimiento normativo: más fácil cumplir RGPD, HIPAA, etc.
Reducción del riesgo legal y reputacional: no hay almacenamiento centralizado que pueda ser atacado.
Colaboración entre entidades: permite explotar el valor agregado de múltiples fuentes de datos sin necesidad de compartirlos.
Eficiencia en ancho de banda y almacenamiento: se transfieren sólo parámetros del modelo, no grandes volúmenes de datos.
A continuación podemos ver una comparativa entre el Aprendizaje Federado y otras tecnologías (PETs):
| Característica | Federated Learning | Otras Tecnologías (PETs) |
|---|---|---|
| Privacidad | ✅ Muy alta: los datos nunca se mueven del origen | ✅ Alta (mediante cifrado, entornos seguros o datos generados) |
| Compartición de datos | ✅ No se comparten datos, solo parámetros del modelo | ❌ Sí, directa o indirectamente (sintéticos, datos cifrados, enclaves) |
| Precisión del modelo | ✅ Alta: se entrena con datos reales en su ubicación | ⚠️ Variable: puede verse afectada (especialmente con datos sintéticos) |
| Colaboración entre organizaciones | ✅ Excelente: permite cooperación sin compartir información sensible | ⚠️ Limitada: requiere acuerdos o tecnologías complejas |
| Escalabilidad | ✅ Alta: funciona desde móviles hasta instituciones globales | ❌ Limitada por coste, hardware o complejidad técnica |
| Coste computacional | ✅ Moderado: entrenamiento local + agregación segura | ❌ Alto (HE/SMPC/TEE) o bajo con menor precisión (sintéticos) |
| Facilidad de adopción | ✅ Alta: existen frameworks maduros listos para usar | ⚠️ Requiere experiencia en criptografía o generación/validación de datos |
| Cumplimiento legal (GDPR, etc.) | ✅ Muy alto: enfoque privacy-by-design | ⚠️ Depende si se implementa correctamente |
El Aprendizaje Federado Horizontal y Vertical son dos enfoques complementarios que permiten adaptar esta tecnología a múltiples escenarios. Ya sea en salud, banca, energía o defensa, elegir el tipo adecuado de FL permite crear modelos más precisos, colaborativos y respetuosos con la privacidad. En un mundo donde los datos son cada vez más valiosos —y sensibles—, el Aprendizaje Federado no es solo una opción técnica: es un requisito estratégico.
En Sherpa.ai llevamos años desarrollando plataformas de Aprendizaje Federado que permiten a nuestros clientes aplicar tanto FL Horizontal como Vertical de forma escalable, segura y conforme a la normativa. Si estás explorando cómo incorporar esta tecnología en tu organización, no dudes en contactarnos.