
In the field of artificial intelligence, having high-quality data is essential for training effective models. Often, the private data needed for AI training is distributed across different devices, such as phones, sensors, or servers. Traditionally, training AI models with such private data requires collecting it in a centralized location, which can be costly, slow, or even illegal due to privacy regulations like data protection laws.
To address this challenge, various approaches exist, such as data sharing through encryption or anonymization techniques, or generating synthetic data. However, these methods all share a common issue: data is still being shared in some form, leading to legal limitations and security/privacy risks. Additionally, continuously sending data to a central server requires substantial bandwidth and infrastructure, increasing operational costs.
Federated Learning (FL) presents an innovative solution by allowing AI models to be trained across distributed datasets without compromising privacy or requiring massive data centralization. Instead of transferring data, FL enables training to occur locally on each device, sharing only model updates rather than the raw data itself. This makes it the only solution that enables AI model training across different data silos without sharing sensitive information.
This represents a paradigm shift—instead of sending data to a central server, the model is sent to the data source. This prevents unnecessary data transfers, ensuring both privacy and security.
What is Federated Learning?
Federated Learning is a distributed machine learning approach that allows AI models to be trained directly on devices that hold the data, eliminating the need to transfer data to a central server. This ensures that data remains locally stored on its original source, such as mobile phones, private servers, or enterprise systems, while only model updates are sent to the central server.
Imagine having data across multiple devices—such as phones or servers—that needs to be used to train an AI model. A traditional approach would require aggregating all data in a central location for processing and training. However, in most cases, this is not feasible due to privacy or security restrictions.
With Federated Learning, data remains on the original device while the model itself is sent to the data source for local training. The only thing shared back to the server is the model’s updated parameters, not the raw data. This way, the model improves collectively while ensuring privacy protection.
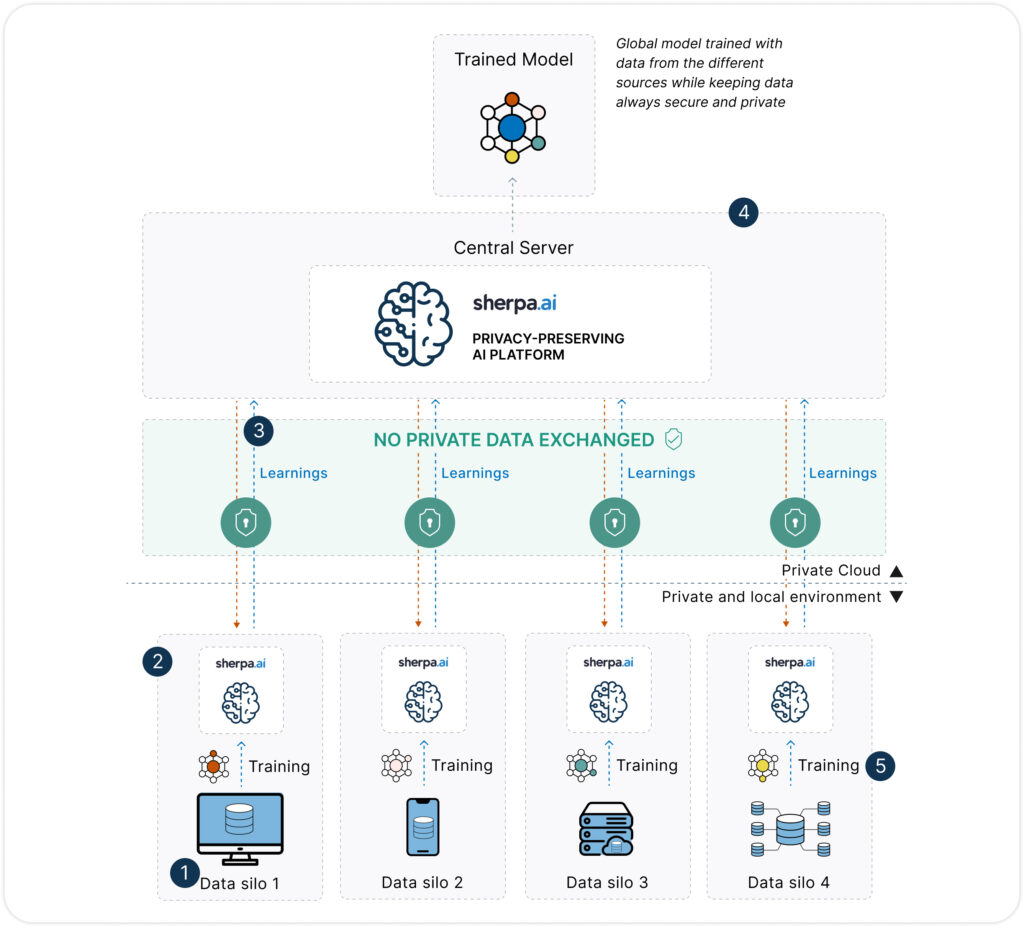
- Data cannot be shared between different silos.
- The software is installed on the node (where the data is located), allowing the model to be trained with local data without sharing it, ensuring that the data never leaves its server.
- Only models are exchanged. The server sends the base model and receives the learnings generated in the nodes.
- The parameters are aggregated in the cloud to generate the global model.
- The final model is privately deployed on each of the nodes.
Federated Learning Architecture
The federated training process involves multiple components that enable collaboration across various devices or entities without data sharing.
Nodes: Devices or servers holding the data and performing local AI model training. These can be on-premise or cloud-based.
Central Server: The orchestrator of the federated learning process, responsible for distributing models to the nodes, aggregating locally trained models, and generating the global AI model.
Federated Learning process
Model Initialization: A base AI model is created on a central server or within a distributed architecture.
Local Training: Devices or local servers receive a copy of the model and train it using their own data.
Parameter Exchange: Instead of sharing data, the devices send model updates back to the central server.
Parameter Aggregation: The updates from multiple nodes are combined to generate an improved global model.
Reiteration: The updated model is redistributed to local nodes for further training cycles.
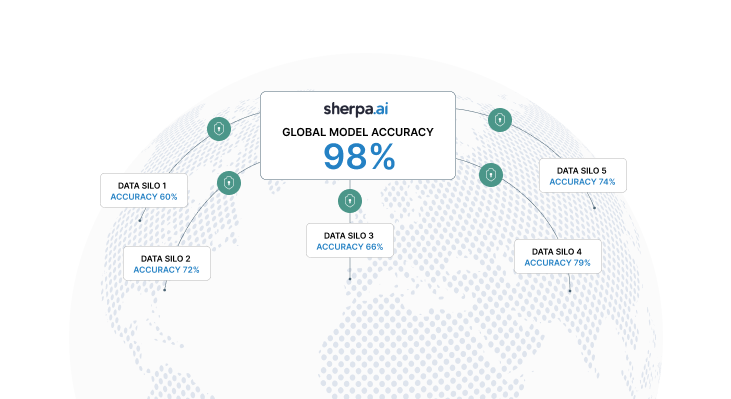
Advantages of Federated Learning
1. Unlocking previously innaccessible data
Federated Learning eliminates the data accessibility problem by allowing AI training on previously restricted datasets due to regulatory, security, or infrastructure limitations.
2. Privacy and Regulatory Compliance
Does not require data sharing or centralized storage, reducing privacy and security risks while ensuring regulatory compliance in sectors such as healthcare, finance, and the public sector.
3. Efficient Use of Bandwidth and Resources
Minimizes data transfer, reducing required resources, bandwidth requirements, and operational costs, especially in environments with limited connectivity. Decentralized training optimizes the use of local resources and accelerates processing without relying on external servers.
4. Optimization of Models in Distributed Environments
By leveraging data from multiple devices or sources without centralizing it, federated learning improves model diversity and accuracy. It also enables device- or user-specific personalization without losing global learning capability.
5. Scalability and Flexibility
Increases model scalability without the need for additional infrastructure, as training occurs on the devices themselves. This makes it an ideal solution for businesses with data across multiple locations or those reliant on mobile and IoT devices.
6. Agile model deployment
Models can be trained and updated in real-time directly on devices, allowing for rapid and adaptive deployment without delays caused by data centralization.
Use cases enabled by Federated Learning
Financial Sector
Fraud prevention – collaboration between different financial institutions.
Churn reduction and conversion improvement – collaboration between commercial banks and insurance companies.
Cross-selling of products – collaboration between insurance companies and commercial banks.
Healthcare and Biomedicine
Personalized diagnosis and treatment – collaboration between different hospitals (health entities).
Discovery of new drugs – collaboration between pharmaceutical companies and healthcare entities.
Industry and Manufacturing
Predictive maintenance – collaboration between different silos (e.g., different factories).
Process optimization – collaboration between different production plants.
Telecommunications
Network optimization – collaboration between different telecommunications companies.
Service personalization – collaboration between telecommunications companies and third parties.
Cybersecurity
Threat detection – collaboration between different data silos.
Protection of sensitive data – collaboration between different data silos.
Internal Collaborations:
Model improvement across countries – collaboration between different countries within a multinational.
Data enrichment across silos – collaboration between different areas within a company.
Conclusion
Federated Learning is revolutionizing how companies use data to train Artificial Intelligence models, offering a scalable, efficient, and, most importantly, privacy-preserving solution. It stands out as the best solution in contexts where data privacy, model quality, and operational efficiency are top priorities.
By enabling to securely and efficiently leverage distributed data, Federated Learning can have a key role in the future of Artificial Intelligence.
In this context, Sherpa.ai positions itself as the most private and secure platform for Federated Learning, enabling companies to train any model without putting their data at risk.