
In today’s data-driven economy, protecting individuals’ privacy is no longer just a legal obligation — it’s a strategic priority. Whether in healthcare, banking, telecom, or public institutions, organizations face a common challenge: how to extract value from data without compromising privacy or violating regulations when trying to collaborate between different data silos.
For years, data anonymization has been the standard method to tackle this issue. However, recent advances in AI and data protection laws (like the GDPR and the EU AI Act) have exposed the limitations of anonymization, and accelerated the adoption of a more powerful approach: Federated Learning.
In this article, we’ll explore the key differences between data anonymization and Federated Learning, highlight the advantages of the latter, and explain why Sherpa.ai offers the most advanced and compliant solution for privacy-preserving AI.
What is Data Anonymization?
Data anonymization is the process of transforming personal data so that it can no longer be linked to an identifiable individual. This is typically done through:
Removal of direct identifiers (names, IDs, emails)
Data masking or pseudonymization
Generalization or aggregation of data values
The idea is that once anonymized, data can be used for analytics or AI training without being considered “personal data” under privacy laws.
However, anonymization comes with serious limitations in practice.
The Critical Limitations of Anonymization
Re-identification risk
Studies have shown that anonymized datasets can be easily re-identified by combining them with other public or semi-public datasets. The infamous Netflix case is a prime example: anonymized movie ratings were cross-referenced with IMDb profiles to identify users.Loss of data quality
Anonymization often removes or distorts valuable information, reducing the precision of analytics and degrading the performance of AI models.Legal uncertainty under GDPR
The GDPR states that if a dataset can be re-identified with “reasonable effort,” it is still considered personal data. This puts many anonymized datasets in a legal gray area — or even in violation.Lack of scalability and flexibility
Anonymization processes are often manual, case-specific, and irreversible. If your analytics objectives change, you may need to re-anonymize from scratch.High energy cost
Anonymization is not computationally free. It requires intensive processing pipelines to detect, transform, and validate sensitive data. Added to this are the energy costs of transferring, storing, and managing multiple versions of the anonymized data. Compared to Federated Learning—which trains directly on data at its source and avoids duplication—anonymization proves to be a less efficient solution from both an energy and operational standpoint.
What is Federated Learning?
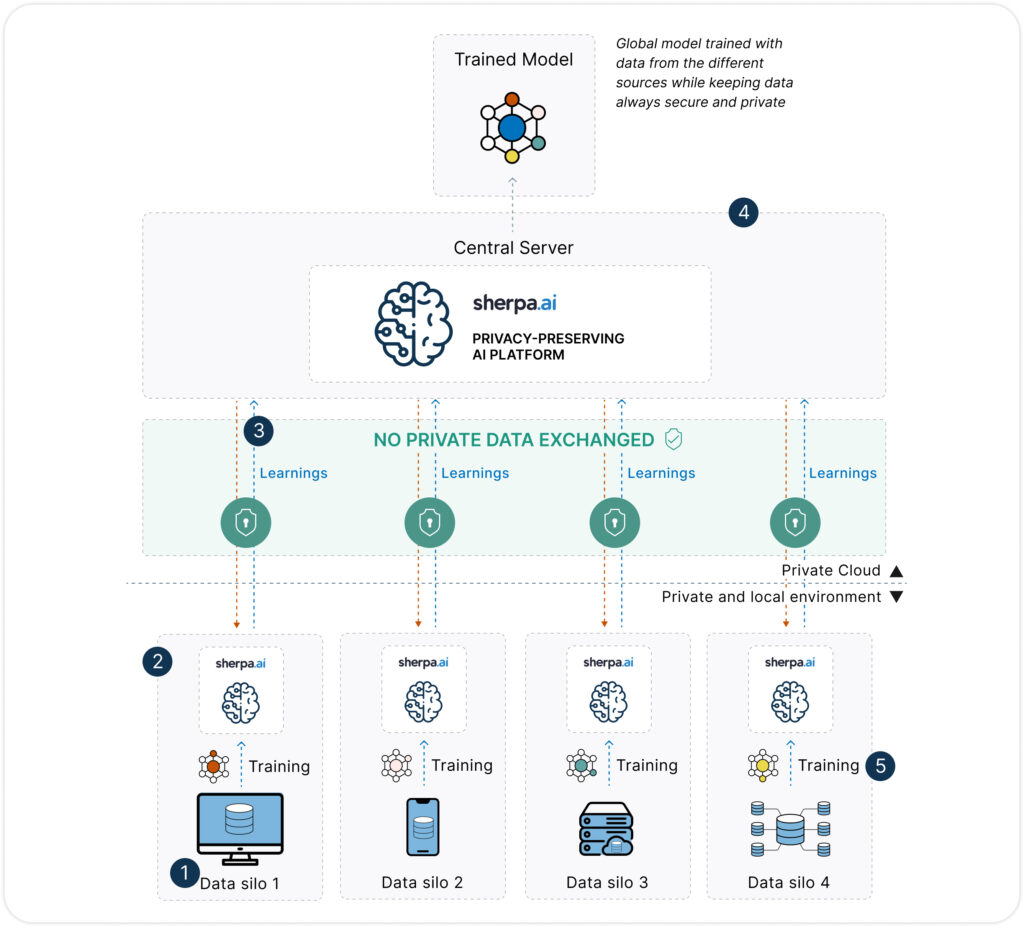
Federated Learning (FL) is an AI paradigm that enables organizations to train models collaboratively without sharing raw data. Instead of centralizing data, each participant trains a local model on their data and shares only model updates (not the data itself) with a coordinating server.
In this way, data remains where it was generated — on-premises, in the cloud, or on user devices — while still contributing to global model performance.
You can find more about what Federated Learning is here
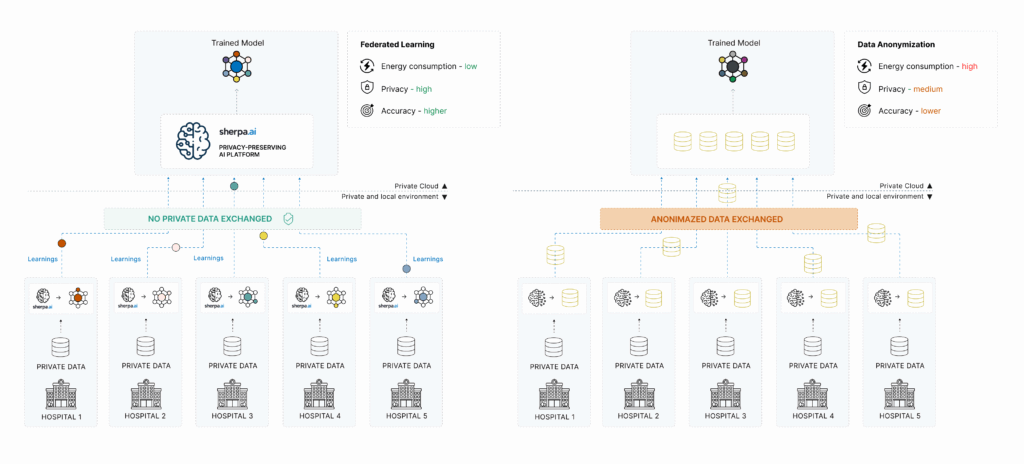
Federated Learning vs. Data Anonymization: A Comparative View
| Category / Dimension | Federated Learning | Data Anonymization |
|---|---|---|
| Privacy | ||
| Privacy & security | ✅ High: no data is transferred. Only model parameters are exchanged. | ⚠️ Residual risk: techniques like k-anonymity don’t guarantee full protection. |
| Need for PII anonymization | ✅ Not required. | ❌ Mandatory: requires formal techniques (k-anonymity, l-diversity, etc.). |
| GDPR compliance | ✅ Strong: aligns with GDPR, HIPAA, etc. since no personal data is moved. | ⚠️ Risky: not all anonymization techniques are legally acceptable. |
| Technical Performance | ||
| Data transmission | ✅ No: data remains local and never leaves its origin. | ❌ Yes: anonymized data must be transferred to a central server. |
| Energy consumption | ⚡ Efficient: avoids duplication and intermediate steps. | 🔋 Medium-high: intensive anonymization and centralized processing required. |
| Model quality | ✅ High: trained on rich, real, distributed data. | ⚠️ Can degrade: anonymization may distort or remove key information. |
| Training time | ✅ Reasonable: enables local and parallel training. | ⏱️ Variable: anonymization can be slow, though central training is often fast. |
| Cost, Scalability & Interpretability | ||
| Implementation cost | ✅ Low: no duplication, transfer, or PII cleansing needed. | ❌ Medium-high: requires anonymization tools, audits, and central data infrastructure. |
| Scalability | ✅ High: works across edge devices, mobile, hospitals, etc. | ⚠️ Limited: depends on central infrastructure and bandwidth. |
In short: Federated Learning not only addresses the shortcomings of anonymization, it also unlocks new opportunities for collaboration and responsible data monetization.
GDPR: Why Anonymization Isn’t Always Enough
Under the General Data Protection Regulation (GDPR), data that is truly anonymized is no longer considered personal data, and therefore falls outside the scope of most privacy restrictions. However, in practice, most anonymization techniques amount to pseudonymization or reversible de-identification. If there is any reasonable way to re-identify an individual, the data still falls under GDPR obligations.
This introduces significant risk for organizations relying on anonymization: they must prove—often with strong technical evidence—that re-identification is virtually impossible. In reality, achieving complete and irreversible anonymity while preserving data utility is extremely difficult. Many experts argue that no valuable dataset is ever truly 100% anonymous.
By contrast, Federated Learning (FL) avoids these pitfalls from the start:
No raw personal data is ever shared — only model updates or parameters are exchanged.
FL aligns with key GDPR principles like data minimization and privacy by design.
Legal processes are simplified, since each data holder remains the controller of their own data.
Emerging frameworks like the EU AI Act favor privacy-preserving approaches that reduce sensitive data transfers, making FL a future-proof strategy.
Of course, Federated Learning still requires proper safeguards: organizations must secure local data and ensure that shared models do not inadvertently leak private information. But compared to anonymization, the legal and regulatory risk is significantly lower.
Platforms like Sherpa.ai support GDPR compliance with features such as:
Full audit trails of the federated training lifecycle,
Built-in Data Protection Impact Assessments (DPIAs),
Support for differential privacy, encryption, and secure aggregation.
GDPR Compliance Comparison Table
| Requirement | Federated Learning (FL) | Data Anonymization |
|---|---|---|
| No raw data is shared | ✅ Yes | ❌ No |
| Data remains under local control | ✅ Yes | ❌ No |
| Easy to demonstrate compliance | ✅ Yes | ❌ No |
| Risk of re-identification | ✅ Very low | ⚠️ Moderate to high |
| Meets GDPR’s “privacy by design” principle | ✅ Yes | ❌ No |
| GDPR exemption (data no longer considered personal) | ✅ Not needed | ❌ Yes (only if truly anonymized) |
| End-to-end auditable privacy workflows | ✅ Yes (Sherpa.ai feature) | ❌ Requires external validation |
| Aligned with future EU AI regulation (e.g., AI Act) | ✅ Fully aligned | ❌ No |
Real-World Examples Where Federated Learning Outperforms Anonymization
Healthcare: hospitals collaborate to train diagnostic models without sharing patient records. Anonymization often fails to protect such sensitive clinical data from re-identification.
Finance: banks and insurers detect fraud patterns together or train better credit scoring models, without having to share sensitive customer information.
Telecom: operators monetize user behavior or mobility patterns by sharing AI model insights with third parties, without exposing raw user data.
Why Sherpa.ai Is the Most Advanced Federated Learning Platform on the Market
In this new privacy-first landscape, Sherpa.ai has built Europe’s most advanced privacy-preserving AI platform, specifically designed for regulated sectors like healthcare, banking, telecom, and government.
What makes Sherpa.ai unique?
Differential privacy built-in
Beyond Federated Learning, Sherpa.ai integrates differential privacy, mathematically ensuring that individual data points cannot be reconstructed from model updates.Full data control for clients
Data never leaves the client’s infrastructure. Sherpa.ai supports on-premise deployment or private cloud setups, ensuring data sovereignty at all times.Auditable and compliant by design
The platform includes tools to document, monitor, and demonstrate GDPR and EU AI Act compliance — a key requirement for enterprise and government deployments.High-performance and interoperable
Sherpa.ai is framework-agnostic (compatible with PyTorch, TensorFlow, etc.), supports scalable orchestration, and is optimized for real-world performance across distributed nodes.Proven in real deployments
Sherpa.ai works with banks, hospitals, telcos and public institutions who are already running Federated Learning projects in production, generating impact while preserving privacy.
Conclusion
As data privacy regulations tighten and customer trust becomes more critical, organizations can no longer rely on outdated or fragile methods like data anonymization. Federated Learning represents a paradigm shift — a way to extract insights, power AI, and collaborate across entities without ever compromising data privacy.
Sherpa.ai is at the forefront of this transformation, offering organizations a future-proof way to leverage their data responsibly, securely, and legally. In the battle between data exploitation and privacy, Federated Learning — powered by Sherpa.ai — is the clear winner.