
The current economy is data-driven, but access to that data is increasingly restricted by regulation, privacy concerns, and technological fragmentation. So how can different organizations — such as banks, insurers, telecom operators, or public institutions — collaborate without compromising privacy or violating regulations like the GDPR or the upcoming EU AI Act?
Two solutions have emerged as viable alternatives: Data Clean Rooms (DCRs) and Federated Learning (FL). Both enable multiple entities to collaborate on data analysis or AI model training without directly sharing raw data.
However, while they share a common goal, their approaches are fundamentally different. In this article, we explore why Federated Learning — as implemented by Sherpa.ai — offers a more secure, efficient, scalable, and more sustainable solution compared to traditional Data Clean Rooms.

What is a Data Clean Room?
A Data Clean Room is a secure environment — typically cloud-based — where different entities can upload their data to perform joint analysis under controlled conditions. DCRs prevent direct access between parties and only allow the execution of queries or the retrieval of pre-approved aggregated insights.
This model has gained popularity in industries such as advertising, media, retail, and banking as a way to enable collaboration without exchanging identifiable data. However, its architecture relies on centralizing data in a common environment, which introduces technical, legal, and performance-related challenges.
Key Limitations of Data Clean Rooms
Although Data Clean Rooms represent progress compared to direct data sharing, their centralized architecture and operational requirements introduce a number of technical, legal, and efficiency-related limitations that must be considered:
1. Dependence on a Centralized Environment
DCRs require each participating entity to upload their data to a shared infrastructure — typically managed by an external provider — which entails:
Loss of data sovereignty,
Exposure risks in the event of security breaches,
Technical and contractual reliance on a third party.
2. Operational and Legal Complexity
To collaborate within a DCR, parties must:
Establish specific legal agreements (DPAs, usage contracts, shared governance),
Validate each analysis or model to be executed,
Coordinate data flows, access permissions, and audits.
This slows down collaboration, reduces agility, and increases administrative costs.
3. Limited Technical Scalability
In multi-party scenarios (e.g., networks of hospitals, banks, or universities), DCRs scale poorly:
They require significant network and storage capacity,
Their performance degrades as the number of participants grows,
They are not designed for edge or distributed environments.
4. Analytical Quality Constraints
For compliance or security reasons, many DCR implementations:
Restrict the types of models that can be applied (e.g., only statistical models or simple regressions),
Limit access to highly granular data,
Do not allow training of complex AI models on real datasets.
This can result in less accurate, less customizable, and ultimately less useful outcomes.
5. High Energy Consumption and Data Duplication
DCRs require:
Full datasets to be copied and transferred into a shared environment,
Multiple rounds of data processing,
Temporary or permanent storage of that data.
This model consumes significant energy and is particularly inefficient when compared to approaches like Federated Learning, which trains directly on data at its original location.
¿What is Federated Learning?
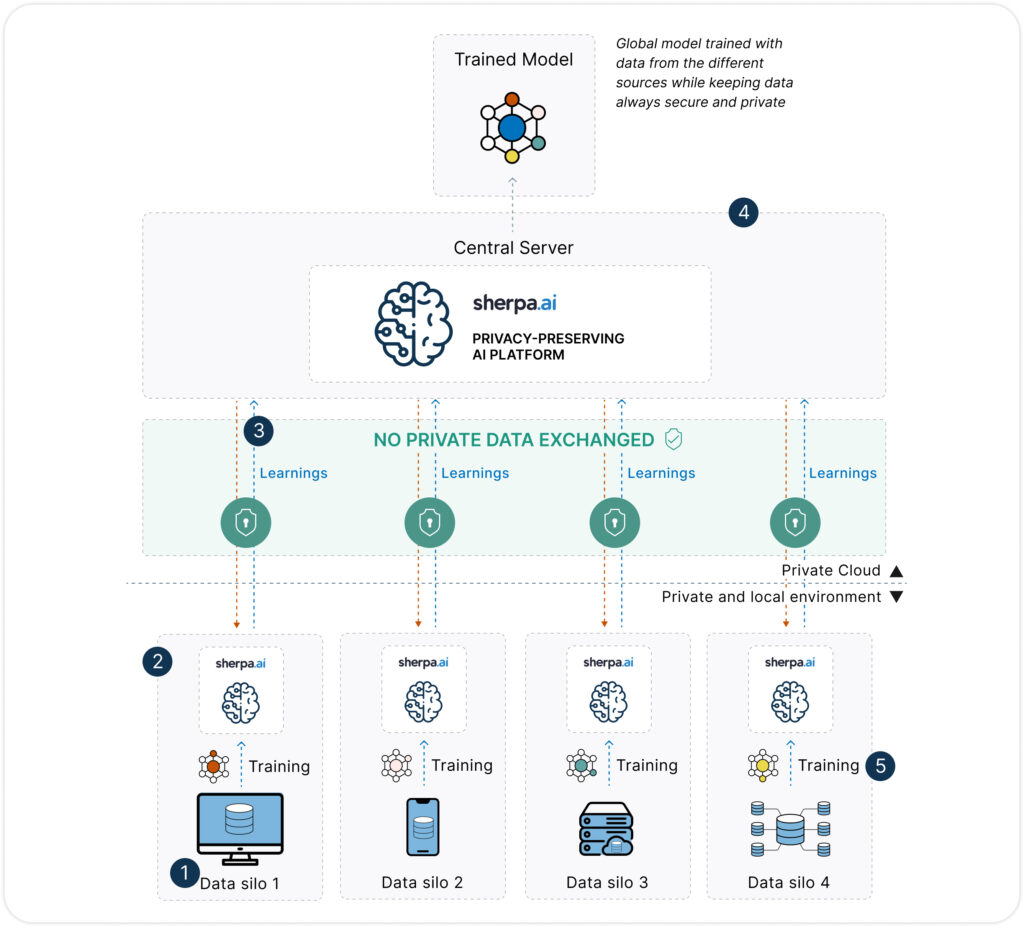
Federated Learning (FL) is an AI model training technique that enables collaborative model development without the need to centralize data. Instead of moving data to a central server, the model is trained locally at each node (such as a hospital, bank, telecom operator, etc.), and only the model parameters — not the data itself — are shared with a coordinating server.
The magic lies in the fact that the data never leaves its original location, which fundamentally changes the traditional approach to data analytics.
If you want to learn more about what Federated Learning, click here.
Federated Learning vs Data Clean Rooms
| Category | Federated Learning | Data Clean Rooms |
|---|---|---|
| Privacy | ||
| Data Transfer | ✅ Data never leaves its original location. | ❌ Requires uploading data to a central environment. |
| Data Control | ✅ Full control: each party retains sovereignty over its data. | ⚠️ Limited: control is delegated to an external provider. |
| GDPR Compliance | ✅ High: no transmission of personal data. | ⚠️ Depends on jurisdiction and environment setup. |
| Differential Privacy | ✅ Yes, built-in by default. | ❌ Not always available or applied. |
| Traceability & Auditing | ✅ Complete: fully available within Sherpa.ai’s platform. | ⚠️ Partial or dependent on the provider. |
| Governance | ||
| Multilateral Collaboration | ✅ Native: multiple parties can collaborate without prior trust. | ⚠️ Requires complex agreements and mutual trust. |
| Integration with Existing Systems | ✅ Easy: no need to redesign infrastructure. | ⚠️ Requires adapting systems to integrate with the DCR environment. |
| Performance | ||
| Technical Scalability | ✅ High: supports edge, on-premise, cloud, and hybrid environments. | ⚠️ Limited: dependent on centralized infrastructure. |
| Speed & Performance | ✅ Native parallelism and distributed training. | ❌ Slow: legal processes, manual reviews, and access delays. |
| Model Quality | ✅ High: trained on real data without loss of granularity. | ⚠️ Limited: often restricted to simplified models or aggregated analyses. |
| Other | ||
| Implementation Cost | ✅ Efficient: no duplication or additional storage needed. | ❌ High: shared infrastructure, validations, legal reviews. |
| Energy Footprint | ✅ Low: local processing and no redundancy. | 🔋 High: requires duplicating, moving, and storing data multiple times. |
Federated Learning vs Data Clean Rooms: Implications for GDPR Compliance
Data Clean Rooms: Conditional Compliance
Although DCRs are designed as controlled environments, they typically require transferring personal—or pseudonymized—data to a shared space, managed by a third party.. This implies that:
A clear legal basis is needed (such as consent, legitimate interest, or contractual necessity),
The environment must be auditable and located within appropriate jurisdictions (e.g., within the EEA),
Organizations remain jointly responsible for data processing activities.
Moreover, the GDPR states that if data can be re-identified using reasonable means, it is still considered personal data — a condition that applies to many datasets used in Clean Rooms, even if pseudonymized or aggregated.
Federated Learning: Native Compliance by Design
Federated Learning, on the other hand, completely avoids the transfer of personal data. Models are trained locally, and only model parameters (such as gradients or weights) are exchanged, which:
Do not contain directly identifiable information,
Can be further protected through differential privacy and secure aggregation,
Do not allow reconstruction of the original dataset when properly implemented.
As a result, FL:
Significantly reduces legal risk,
Aligns with the principles of privacy by design and by default,
Eliminates the need to share personal data between entities.
Additionally, each organization retains its role as the data controller, simplifying responsibility flows and Data Protection Impact Assessments (DPIAs).
GDPR Compliance Comparison
| Legal Criterion | Federated Learning | Data Clean Rooms |
|---|---|---|
| Are personal data transferred? | ✅ No | ❌ Yes (even if pseudonymized) |
| Is there shared responsibility? | ✅ No | ❌ Yes (joint controllers) |
| Is “privacy by design” fulfilled? | ✅ Natively | ⚠️ Depends on configuration |
| Can consent be avoided? | ✅ In many cases (legitimate interest + FL) | ⚠️ Not always (requires clear legal basis) |
| Is data storage required? | ✅ No | ❌ Yes, in a common environment |
| Aligned with the AI Act? | ✅ Yes, explicitly favored | ⚠️ Under review (not guaranteed) |
Real-World Use Cases Where Federated Learning Outperforms Data Clean Rooms
Although Data Clean Rooms have gained popularity in sectors like digital marketing, there are numerous real-world scenarios where Federated Learning (FL) is clearly superior — especially when privacy, accuracy, and flexibility are critical. Below are some representative examples:
1. Collaboration Between Hospitals for Medical Diagnosis
The challenge: Multiple healthcare institutions want to jointly train an AI model to help diagnose rare diseases using medical imaging. However, clinical data is extremely sensitive and protected under laws like the GDPR and HIPAA.
Why not DCR?
Uploading anonymized medical images to a shared environment not only involves a complex legal process but also reduces diagnostic quality, as anonymization strips away clinically relevant metadata.
Why FL?
With Federated Learning, each hospital trains locally on its original images, preserving data fidelity and privacy. Sherpa.ai ensures that personal data never leaves the hospital environment, thereby supporting compliance with data protection regulations.
2. Fraud Prevention Across Competing Banks
The challenge: Several financial institutions want to detect fraud patterns that span across multiple banks (e.g., cloned cards used at different institutions).
Why not DCR?
A Data Clean Room would require banks to share transaction data in a common environment, which is both legally and operationally unfeasible due to competition and financial data sensitivity.
Why FL?
With FL, each bank trains the model on its own transactions, without sharing data with competitors. The model learns to detect complex fraud patterns while preserving privacy and banking secrecy — and without any legal friction between entities.
3. Joint Campaign Optimization Between Telcos and Third Parties (Retail, Airlines…)
The challenge: A mobile operator wants to collaborate with an airline and a retail chain to offer personalized promotions to frequent users. Each company has valuable but fragmented data.
Why not DCR?
Using a DCR across three separate entities requires a high level of trust and complex multilateral legal agreements, along with data standardization and audit processes.
Why FL?
Federated Learning allows each party to train locally on its own data, contributing to a shared model without revealing anything to the others. This enables large-scale personalization without legal friction or data exposure.
4. Predictive Maintenance in Multisector Industrial Networks
The challenge: Manufacturers of industrial components want to collaborate to anticipate equipment failures across globally distributed assets. Each company collects sensor data under real operating conditions.
Why not DCR?
Centralizing this data in a Data Clean Room would require moving large volumes of information from factories or edge devices, which is costly and technically impractical.
Why FL?
FL can run directly on devices or local gateways, training models in industrial environments without transferring data to a central location. It’s more efficient, more secure, and far more scalable than a centralized approach.
Sherpa.ai: The Most Advanced Federated Learning Platform on the Market
In this new privacy-first landscape, Sherpa.ai has built Europe’s most advanced privacy-preserving AI platform, specifically designed for regulated sectors like healthcare, banking, telecom, and government.
What makes Sherpa.ai unique?
Differential privacy built-in
Beyond Federated Learning, Sherpa.ai integrates differential privacy, mathematically ensuring that individual data points cannot be reconstructed from model updates.Full data control for clients
Data never leaves the client’s infrastructure. Sherpa.ai supports on-premise deployment or private cloud setups, ensuring data sovereignty at all times.Auditable and compliant by design
The platform includes tools to document, monitor, and demonstrate GDPR and EU AI Act compliance — a key requirement for enterprise and government deployments.High-performance and interoperable
Sherpa.ai is framework-agnostic (compatible with PyTorch, TensorFlow, etc.), supports scalable orchestration, and is optimized for real-world performance across distributed nodes.Proven in real deployments
Sherpa.ai works with banks, hospitals, telcos and public institutions who are already running Federated Learning projects in production, generating impact while preserving privacy.
Conclusion
Data Clean Rooms have marked a significant step forward in data-driven collaboration, particularly in sectors like advertising and marketing. However, their centralized approach, operational complexity, and technical limitations make them inadequate for scenarios where privacy, scalability, and accuracy are critical.
Federated Learning, as implemented by Sherpa.ai, offers a more robust, secure, and sustainable alternative — a technology that enables collaboration without data sharing, in a scalable, auditable, and regulation-compliant manner.
In the new paradigm of responsible AI, privacy isn’t a barrier — it’s a strategic advantage.