
For decades, the development of Artificial Intelligence (AI) has been closely tied to the mass collection of data in centralized servers. This approach has enabled major advances—from prediction models to virtual assistants and recommendation systems. However, as the sensitivity of data has increased—especially in sectors like healthcare, finance, or defense—so too have the risks associated with centralization.
In response to this traditional paradigm, Federated Learning has emerged as a solution that allows AI models to be trained without the need to move data from its original location. This new approach not only improves privacy but also opens the door to more secure collaboration between organizations while complying with the strictest legal frameworks.
In this article, we compare the classic centralized data approach with the disruptive proposal of Federated Learning, analyzing their advantages, limitations, and most relevant use cases.
The Traditional Approach: Centralizing Data
In the traditional AI model, data is collected and transferred to a central repository—such as a server, data center, or public cloud—where machine learning models are trained. This process enables all the data to be available in one place, facilitating technical development and model optimization.
Advantages of centralized data:
Accessibility: Data scientists can access all the information without worrying about source fragmentation.
Technical simplicity: No need for a distributed architecture or complex synchronization mechanisms.
Mature ecosystem: Consolidated tools and standardized procedures exist for model training in centralized environments.
However, these advantages are increasingly overshadowed by critical risks and limitations:
Security vulnerabilities: Concentrating massive volumes of data in one location increases the attack surface for cyber threats.
Privacy concerns: Transferring data often exposes personal or sensitive information, potentially violating users’ rights.
Regulatory compliance: Laws like the GDPR in Europe, CCPA in California, or the EU AI Act impose strict limits on how data is collected, stored, and processed.
Logistical limitations: In distributed environments like hospitals, banks, or IoT devices, moving all data to a central server can be costly, slow, or even unfeasible.
Federated Learning: Privacy Without Sacrificing Intelligence
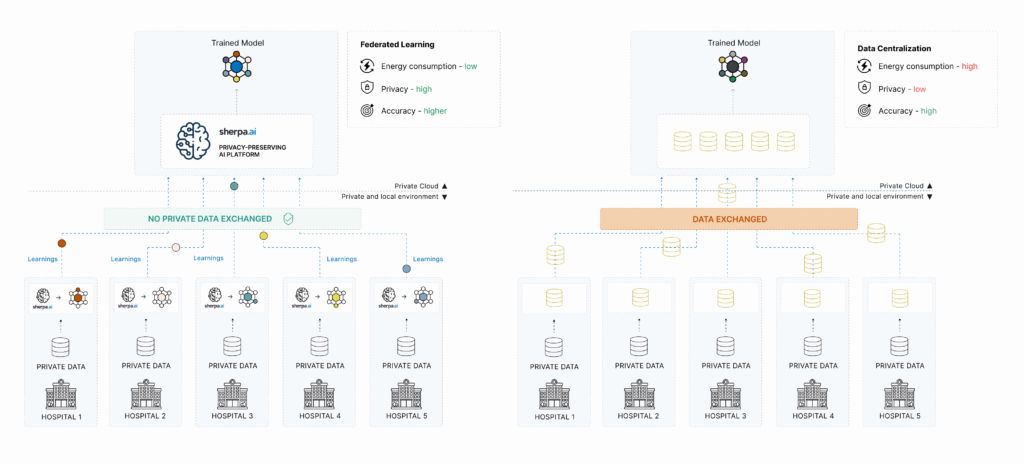
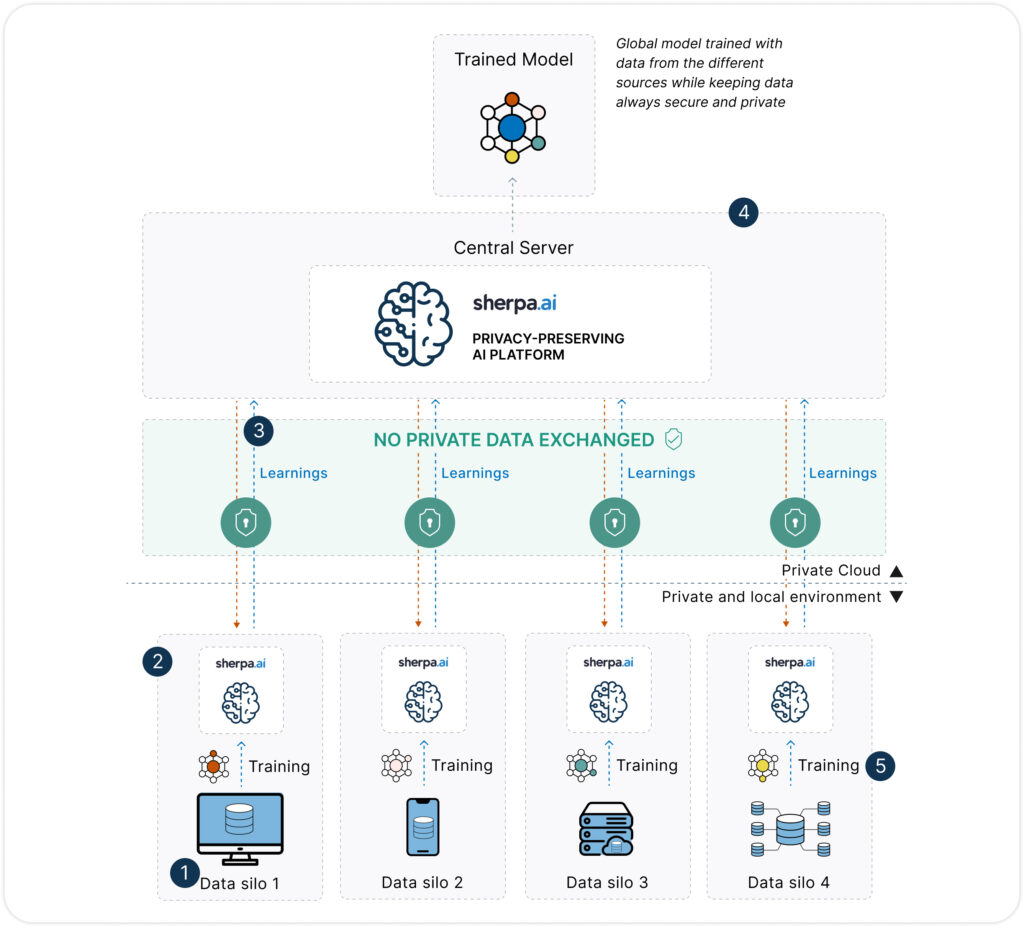
Federated Learning proposes a paradigm shift: instead of centralizing data, the model is trained in a distributed manner by sending algorithms to the places where the data resides (devices, local servers, private nodes, etc.). Models learn locally, and only updates (such as gradients or weights) are shared with a central server, which aggregates them without accessing the original data.
Key benefits of Federated Learning:
Privacy by design: Data never leaves its source, drastically reducing the risk of exposure.
Better legal compliance: The approach facilitates adherence to strict regulatory frameworks, even across borders.
Scalability: Enables training models across millions of devices or distributed locations without transferring large data volumes.
Secure collaboration: Competing organizations (banks, insurers, hospitals) can collaborate to train shared models without exchanging sensitive data.
In addition, Sherpa.ai has combined Federated Learning with technologies such as:
Differential privacy: Adds statistical noise to prevent individual identification.
Homomorphic encryption: Enables operations on encrypted data.
Secure Multi-Party Computation (SMPC): Splits and processes data jointly without any party accessing the full dataset.
Want to learn more about Federated Learning? Click here.
Side-by-Side Comparison: Federated Learning vs Centralized Data
Here’s a summary of the main differences between both approaches:
| Category | Federated Learning | Centralized Data |
|---|---|---|
| Privacy | ||
| Privacy & security | ✅ High: data never leaves its origin; only model updates are exchanged. | ❌ Low: all data is gathered in one place, increasing vulnerability and risk. |
| Prior anonymization (PII) | ✅ Not needed: training happens locally, reducing the need for anonymization. | ❌ Required: sensitive data often needs to be anonymized before aggregation. |
| Regulatory compliance (GDPR, HIPAA) | ✅ Strong: by not moving personal data, compliance is easier. | ❌ Challenging: data movement and storage require strict legal safeguards. |
| Performance | ||
| Data transmission | ✅ None: only model parameters are sent, not raw data. | ❌ Required: raw data must be transmitted to a central server. |
| Energy consumption | ✅ Efficient: avoids data duplication and centralized infrastructure overhead. | ❌ High: requires massive storage, transfer, and processing resources. |
| Model quality | ✅ High: trained on real, current, and contextual data. | ⚠️ High: trained on complete datasets, but at the expense of privacy and flexibility. |
| Training time | ✅ Efficient: parallel, distributed training enables faster iteration. | ❌ Variable: depends on data aggregation and central processing speed. |
| Scalability | ||
| Cross-entity collaboration | ✅ Secure: enables model sharing across organizations without sharing raw data. | ❌ Limited: legal, technical, and trust barriers hinder collaboration. |
| Scalability | ✅ High: works across edge, hospitals, banks, etc., without data consolidation. | ❌ Limited: centralization becomes less viable at larger scales. |
| Latency | ✅ Low: local training reduces delays. | ❌ High: data transfers introduce latency and bottlenecks. |
| Cost | ||
| Implementation cost | ✅ Optimized: avoids data duplication, transfer, and legal complexity. | ❌ Expensive: requires centralized infrastructure and compliance mechanisms. |
| Maintenance & updates | ✅ Flexible: local updates can be deployed without system-wide interruptions. | ❌ Centralized: updates must be propagated from a single system, often with downtime. |
| Governance | ||
| Data sovereignty | ✅ Preserved: each organization retains full control over its data and models. | ❌ Reduced: once centralized, ownership becomes blurred. |
| Auditability & traceability | ✅ High: local logs and controlled training preserve traceability. | ❌ Low: hard to track data lineage in a unified central dataset. |
Which Approach Should You Choose?
There’s no one-size-fits-all answer. Both approaches can be valid depending on the use case, existing data architecture, legal requirements, and business objectives.
Centralized data may still be useful when:
AI projects already operate with centralized data by design.
Privacy is not a critical concern.
Budget or technical limitations prevent federated infrastructure deployment.
Federated Learning is clearly superior when:
Healthcare: train predictive models without extracting medical data from hospitals or clinics.
Finance: enable collaboration between banks or insurers without sharing individual transactions.
Defense and security: extract value from sensitive data without compromising sovereignty or confidentiality.
IoT and edge computing: train models on devices, sensors, or connected vehicles without aggregating data.
A Paradigm Shift in AI
The question is no longer whether we can centralize data—but whether we should. In a world where privacy, data sovereignty, and security are top priorities, the organizations that lead the shift toward ethical, sustainable, and collaborative AI will also lead the next generation of innovation.
At Sherpa.ai, we are fully committed to this transition. Our Federated Learning platform enables businesses and institutions to train AI models securely, privately, and efficiently—without ever sharing their data. Thanks to our technology, sectors such as healthcare, banking, industry, and government are already embracing a more responsible kind of AI.
Sherpa.ai: The Most Advanced Federated Learning Platform in the Market
Sherpa.ai has developed Europe’s most powerful and complete Federated AI platform, specifically designed to address privacy, security, and compliance challenges in the most demanding industries.
What makes Sherpa.ai’s platform unique?
Built-in differential privacy: models are not only trained without sharing data, but mathematical perturbations are added to prevent data reconstruction.
Client-controlled: data never leaves the client’s environment. The platform can be deployed on-premises or in a private cloud, ensuring sovereignty.
Auditability and compliance: includes tools to demonstrate compliance with GDPR, the EU AI Act, and sector-specific regulations.
High interoperability and performance: compatible with AI frameworks (TensorFlow, PyTorch, etc.), with advanced node orchestration and efficient communication.
Proven in production: Sherpa.ai is already working with banks, hospitals, telcos, and public agencies using Federated AI to extract value from data without compromising privacy.
Conclusion
For a long time, it was assumed that building accurate AI models required sacrificing privacy. Federated Learning proves that this trade-off is no longer necessary. Today, it is possible to build equally or even more powerful models while complying with regulations and respecting data confidentiality.
The future of AI will not only be smarter—it will also be more private, ethical, and collaborative.
And that future starts today.