
In a world increasingly driven by artificial intelligence and data, privacy has become one of the greatest technological, ethical, and regulatory challenges. Companies, governments, and organizations across all sectors are seeking ways to extract value from data without compromising the confidentiality of individuals or entities involved.
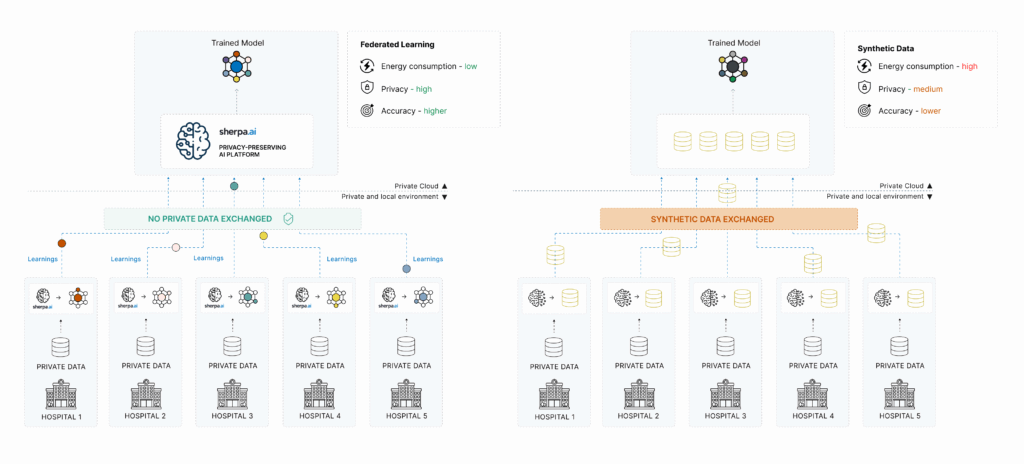
Among the many approaches that have emerged to address this dilemma, two technologies stand out: synthetic data and Federated Learning (FL). Both aim to protect privacy in AI environments—but they do so through radically different strategies.
At Sherpa.ai, after years of research and development in computational privacy, we believe Federated Learning represents a more robust, realistic, and scalable solution to today’s privacy challenges. Here’s why.
What is synthetic data, and why is it gaining popularity?
Synthetic data is artificially generated data produced by algorithms that learn the statistical characteristics of real datasets. In other words, it doesn’t correspond to actual individuals, but it mimics their behavior and patterns.
This technique has become especially popular in sectors such as healthcare, finance, and marketing, where access to real data is highly restricted due to regulations like GDPR (Europe) or HIPAA (U.S.).
Initial advantages of synthetic data:
Avoids the direct use of real data, reducing legal risk.
Facilitates data sharing and collaboration between institutions.
Accelerates AI model development where real data access is limited.
But... what are its limitations?
Despite its advantages, synthetic data has structural limitations that affect its effectiveness:
Privacy risks remain: If the generator model isn’t properly protected, or if the real data is highly sensitive, leakage or reconstruction is possible.
Less accurate models: Synthetic data often reduces training quality, especially when real patterns are complex or rare.
Doesn’t solve data governance issues: Even without sharing real data, there’s still uncertainty around who can access, use, and validate synthetic data.
Not suitable for real-time use: The generation and validation of synthetic data takes time, limiting its applicability in live data flow scenarios (e.g., edge, IoT, cybersecurity).
Federated Learning: Privacy by design
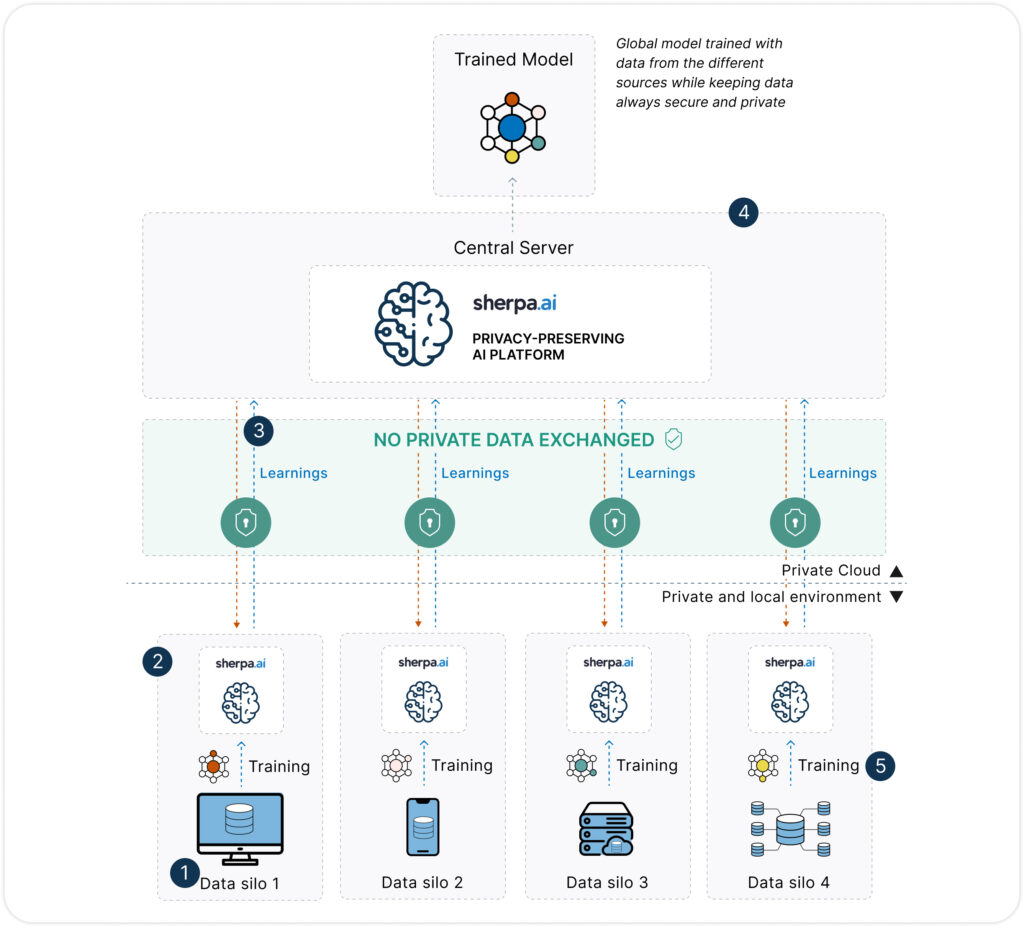
Unlike synthetic data, Federated Learning proposes a radical shift: instead of moving data to the model, it moves the model to the data. This allows each organization or device to train a local copy of the model on its own data, sharing only model updates—not the data itself.
Key benefits of Federated Learning:
True privacy: data never leaves its source.
Regulation by design, fully compliant with data protection laws.
Higher fidelity: trained directly on real data—no need to simulate it.
Scalable and adaptable to various environments: edge computing, mobile devices, hospitals, or sovereign data platforms.
If you want to learn more about what Federated Learning is, check here.
Advantages of Federated Learning over Synthetic Data
| Category / Dimension | Federated Learning | Synthetic Data |
|---|---|---|
| Privacy | ||
| Privacy & security | ✅ High: data is never shared; only model updates are exchanged. | ⚠️ Limited: data isn’t real, but the generator model can leak patterns. |
| Prior anonymization (PII) | ✅ Not needed: training happens at the source without accessing the data. | ❌ Caution required: generator is trained on real data. |
| Regulatory compliance (GDPR) | ✅ Strong: aligned with GDPR, HIPAA, etc., by not moving personal data. | ⚠️ Risky: if synthetic data is too similar, it may still fall under regulation. |
| Performance | ||
| Data transmission | ✅ None: data never leaves its origin. | ❌ Yes: synthetic data must be stored, shared, and managed like any dataset. |
| Energy consumption | ✅ Efficient: no duplication or intermediate generation. | ⚠️ Medium-high: generation process is intensive, especially with generative models. |
| Model quality | ✅ High: trained on real and current data. | ⚠️ Variable: may degrade if data doesn’t reflect real-world complexity. |
| Training time | ✅ Reasonable: local, parallel training across nodes. | ⏱️ Slow: generation + validation can exceed training time. |
| Other | ||
| Implementation cost | ✅ Low: no duplication, transfer, or complex legal requirements. | ❌ Medium-high: requires generation tools, validation processes, and storage. |
| Scalability | ✅ High: adaptable to devices, edge, hospitals, banking, etc. | ⚠️ Limited: generating high-quality synthetic data at scale requires significant resources. |
| Interpretability & governance | ✅ High: each organization controls its data, node, and model. | ⚠️ Ambiguous: hard to audit traceability of synthetic data and its usage. |
Do synthetic data comply with GDPR? Not always.
Though often marketed as a “safe” and “legal” way to avoid using personal data, synthetic data does not automatically guarantee compliance with the General Data Protection Regulation (GDPR). This is a common misconception in both tech and legal circles.
GDPR does not explicitly define or regulate synthetic data—but it does state that any information that can directly or indirectly identify a person is considered personal data. If synthetic datasets can infer or reconstruct information about real individuals (which can happen if the generator memorizes sensitive patterns), then those datasets are still subject to GDPR.
Main legal risks with synthetic data:
Reidentification risk: If the model was trained on real data without privacy-preserving techniques (e.g., differential privacy), it could leak actual records.
Anonymization not guaranteed: GDPR requires irreversible anonymization—something that’s hard to prove with synthetic data.
Traceability issues: Once shared, it’s difficult to audit where the data came from or whether it respects legal principles.
Challenges with the right to be forgotten: If a person requests data deletion, it’s nearly impossible to remove their influence if embedded in a synthetic dataset.
- Statistical distribution as a form of disclosure: Even if the data is anonymized or synthesized, for an AI model to function correctly during inference, the data must preserve a statistical distribution very similar to that of the original data. This requirement means that part of the underlying information has already been revealed or encoded in the synthetic data, which may carry legal implications—especially if that distribution reflects sensitive or identifiable patterns.
Why Federated Learning is a better fit
Federated Learning doesn’t require generating or manipulating data. It simply allows models to be trained directly where the data resides—no copying, no movement. This reduces legal risk and naturally aligns with GDPR principles: data minimization, purpose limitation, integrity, security, traceability, and accountability.
Instead of trying to “transform” data to no longer be personal, like the synthetic approach, Federated Learning preserves privacy by design: the data never moves, is never replicated, and always remains under the control of its owner.
Real-world use cases where Federated Learning outperforms synthetic data
While synthetic data may be useful for sandbox environments or sharing example datasets, there are many real-world scenarios where Federated Learning is clearly more effective, secure, and applicable—especially in regulated sectors, real-time data flows, or inter-organizational collaboration.
1. Healthcare and hospitals
Challenge: Medical records contain extremely sensitive information. Even anonymized or synthetic versions raise legal and ethical concerns.
FL solution: Enables training of diagnostic or treatment recommendation models without moving patient data.
✅ Guaranteed privacy, ✅ legal compliance, ✅ live, real data.
2. Banking and insurance
Challenge: Financial institutions cannot share customer data. Synthetic generation may distort real risk behaviors.
FL solution: Allows fraud detection or risk estimation across banks without database sharing.
✅ Accurate models, ✅ business confidentiality, ✅ secure collaboration.
3. Public administrations and census data
Challenge: Handling demographic or fiscal data involves high privacy risk.
FL solution: Trains models for urban planning or mobility while preserving data sovereignty of each region.
✅ Decentralization, ✅ digital sovereignty, ✅ transparency.
4. Collaborative cybersecurity
Challenge: Organizations face different threats, but can’t share logs or traffic patterns due to privacy and confidentiality concerns.
FL solution: Trains threat detection models within each entity’s infrastructure.
✅ Real-time protection, ✅ data confidentiality, ✅ collective intelligence.
5. Industry and IoT
Challenge: Data from sensors in factories or connected devices is massive, sensitive, and heterogeneous.
FL solution: Enables predictive maintenance or failure detection without sending data to the cloud.
✅ Low latency, ✅ energy efficiency, ✅ edge-ready.
Sherpa.ai: The most advanced Federated Learning platform on the market
In this context, Sherpa.ai has developed the most powerful and complete Federated AI platform in Europe, specifically designed to solve privacy, security, and compliance challenges in demanding sectors.
What makes Sherpa.ai’s platform unique?
Integrated differential privacy: Not only is data never shared, but mathematical noise is applied to prevent reconstruction from model parameters.
Total customer control: Data never leaves the client’s environment. The platform can be deployed on-premise or in private cloud—ensuring data sovereignty.
Auditability and traceability: Tools included to prove compliance with GDPR, the EU AI Act, and other sector-specific regulations.
High performance and interoperability: Compatible with major AI frameworks (TensorFlow, PyTorch), supports advanced node orchestration and efficient communication.
Proven in production: Sherpa.ai is already working with banks, hospitals, telcos, and public institutions using Federated AI to extract value without compromising privacy.
Conclusion
Synthetic data can be useful in very specific cases, especially for testing or as a temporary substitute. However, it’s not a comprehensive solution to the privacy problem.
Federated Learning, on the other hand, offers an architecture that respects data sovereignty, enables collective intelligence, and complies with regulation by design. In a context where trust is paramount, this approach is not only safer—it’s also more effective and sustainable.
At Sherpa.ai, we believe privacy should not be a barrier to innovation—it should be the foundation. That’s why Federated Learning is at the heart of our technology.