Introduction
The growing use of data in artificial intelligence (AI) has driven the need for methods that protect information privacy without compromising its utility. Two of the most widely used strategies for this purpose are data anonymization and federated learning (FL).
While both techniques aim to ensure data privacy, they have fundamental differences in terms of security, efficiency, and regulatory compliance.
This article explores how these two strategies work, their key differences, and why federated learning is often the better option for preserving privacy without sacrificing data value.
What Is Data Anonymization?
Anonymization is a process that modifies personal data to prevent individuals from being identified. Its goal is to enable data use and analysis without compromising user privacy.
How Data Anonymization Works
- Removal or modification of personal identifiers – Data such as names, addresses, and phone numbers are removed to prevent direct linkage to an individual.
- Masking techniques – Methods such as aggregation, generalization, or randomization are applied to reduce the risk of reidentification.
- Synthetic data generation – In some cases, artificial datasets are created that maintain similar statistical characteristics to the original data without containing real information.
Benefits of Data Anonymization
- Regulatory compliance – Meets privacy regulations such as GDPR and CCPA by reducing the risk of personal data exposure.
- Facilitates data sharing – Enables the exchange of data without revealing sensitive information.
- Reduces legal and security risks – Minimizes the potential for personal data breaches.
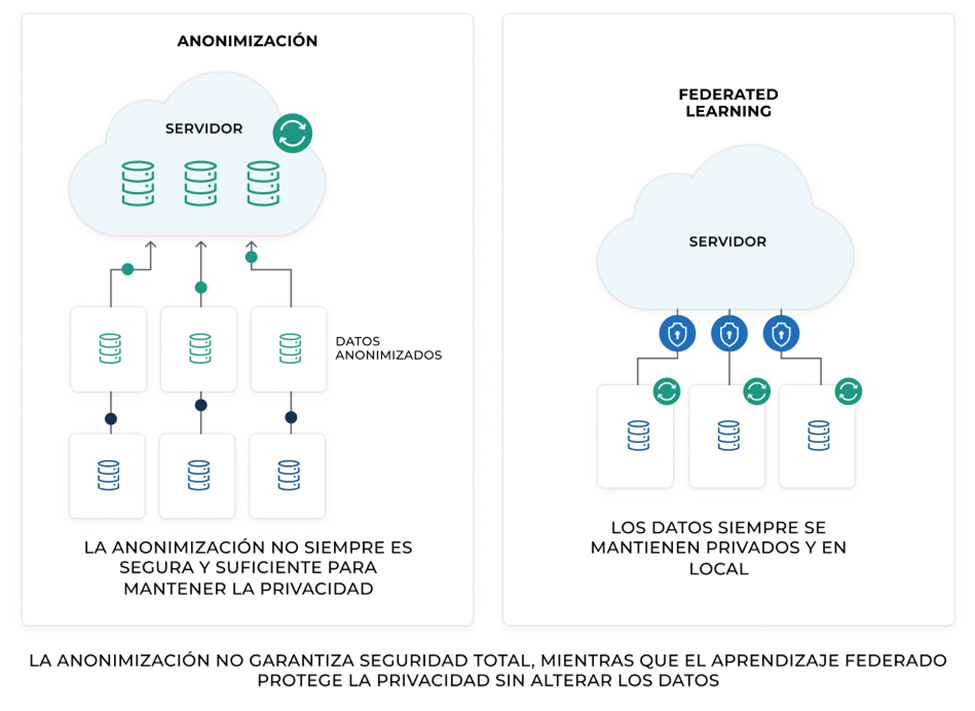
However, anonymization has significant limitations. One of the main issues is that anonymized data can be reidentified using advanced correlation or machine learning techniques, especially when combined with other publicly available datasets.
What Is Federated Learning?
Federated Learning (FL) is an AI method that allows training models without transferring data to a central server. Instead of collecting information in a single database, FL enables models to be trained on the devices or servers where the data resides, ensuring that information never leaves its origin.
How Federated Learning Works
- Model distribution – An initial model is sent to devices or servers with local data.
- On-device training – Each node trains the model using its own data without sharing it.
- Sending updated parameters – Only model updates are transmitted, not the data itself.
- Global aggregation – A central server combines the updates to improve the global model without accessing the original information.
Benefits of Federated Learning
- Enhanced privacy – Data remains in its original location, reducing the risk of leaks.
- Higher accuracy and utility – Unlike anonymization, no relevant information is lost in the process.
- Regulatory compliance – Facilitates adherence to regulations by avoiding the need to centralize personal data.
- Computational efficiency – Reduces data transfer, optimizing bandwidth and storage.
Comparison: Federated Learning vs. Data Anonymization
| Feature | Federated Learning (FL) | Data Anonymization |
|---|---|---|
| Data Privacy | Data never leaves its origin. | Data is modified to hide personal information. |
| Analysis Efficiency | Preserves data integrity, allowing AI models to be trained without loss of information. | May degrade data quality and reduce its utility. |
| Reidentification Risk | Very low, as data is never shared or transferred. | High, as data can be correlated with other sources. |
| Regulatory Compliance | Facilitates compliance with GDPR, HIPAA, etc. | May comply with regulations, but reidentification risk can create legal issues. |
| Scalability & Applicability | Highly scalable across industries (healthcare, finance, telecom, etc.). | Limited to cases where data precision loss is not a critical issue. |
| Data Security | Greater security by not exposing data to third parties. | May be vulnerable to reidentification attacks. |
Advantages of Federated Learning Over Data Anonymization
Although data anonymization has been a traditional solution for protecting privacy, federated learning offers significant advantages in terms of security, accuracy, and scalability:
- Lower Risk of Reidentification
- Data never leaves its original source, preventing exposure to external attacks.
- Anonymization, in contrast, can be vulnerable to correlation techniques and inference attacks.
- Higher Accuracy and Data Quality
- Anonymization can distort information, reducing AI model effectiveness.
- With federated learning, data remains in its original format, ensuring more precise and robust models.
- Simplified Regulatory Compliance
- FL makes it easier to adhere to regulations like GDPR and HIPAA by avoiding sensitive data transfers.
- Anonymization can be problematic if data can be reidentified.
- Scalability and Adaptability
- FL is ideal for distributed environments such as banks, hospitals, and IoT devices, where data is decentralized.
- Anonymization requires additional processing before data can be shared, which can be costly and difficult to implement at scale.
Conclusion
Data privacy is a key challenge in the era of artificial intelligence. While anonymization has been a traditional approach, its limitations in security, accuracy, and regulatory compliance make it insufficient in many cases.
Federated learning emerges as a safer and more efficient alternative, allowing AI models to be trained without sharing sensitive data, reducing leak risks, and improving analytical accuracy.
For companies in industries such as healthcare, banking, insurance, and telecommunications, FL not only protects privacy but also enables them to maximize the value of their data without compromising security or regulatory compliance.
The future of AI depends on methods that balance privacy and performance, and federated learning is proving to be one of the most promising solutions to achieve this.